SEO 入门指南-Ch4:搜索引擎友好的设计和开发
2017-12-09 [seo
]
SEO 入门指南-Ch4:搜索引擎友好的设计和开发
搜索引擎在如何爬取并翻译信息这方面有些局限。 同一个网页,在不同的搜索引擎里看起来可能是不一样的。 在这一节,我们将重点讨论如何构建对搜索引擎和真实用户一致的网页的技术细节。
TL. DR.
1. 可被索引的内容
为了在更多的搜索引擎里表现良好,网页最重要的内容应该以 html 文本的格式出现。
图片,Flash 文件, Java Applet 等其他非文本的内容通常会被搜索引擎的爬虫忽略。
确保你对用户展现的词汇和短语对搜索引擎可见的最容易的方式就是以 html 文本格式在页面上。
然而,为了更好的格式化和可视化体验,有很多高级选项可供选择:
- 为
img设置alt属性。设置图片的alt属性就为爬虫提供了关于图片的可视化描述。 - 为搜索框填充导航,可被爬取的链接。
- 为 Flash 或者 Java 插件填充文本。
- 为
video,audio标签提供一份冗余脚本便于被搜索引擎索引。
1.1 以搜索引擎的视角审视你的网站
很多网站在被索引内容上存在重要的问题,多次检查值得做。 使用像 Google Cache, SEO-browser.com 还有 MozBar 等工具你可以看到页面上哪些内容是对搜索引擎可见的。 看看下面的 Google 页面缓存,看出不同来了吗?
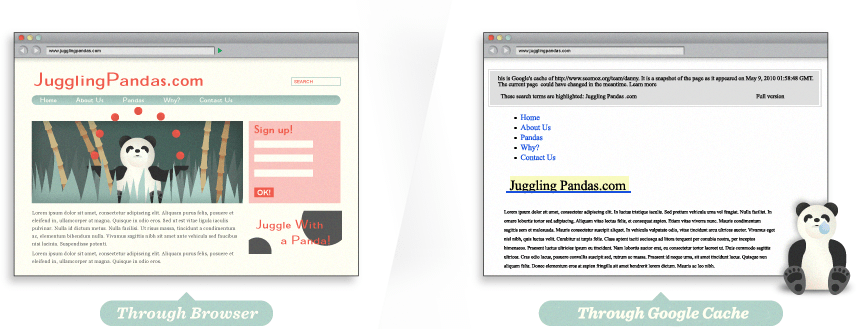
1.2 哇,那是我们看上去的样子吗
使用 Google 缓存的特性,我们看到对搜索引擎来说,JugglingPandas.com 的首页并不包含所有我们看到的富媒体内容。 这就让搜索引擎很难解析它的相关性。
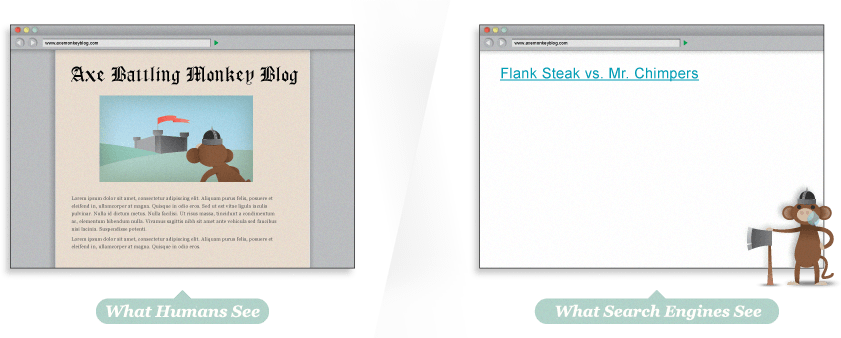
1.3 嘿,有趣的内容去哪了
通过 Google 缓存,我们看到这个页面几乎是一片荒芜。
甚至没有文本告诉我们这个页面包含 Axe Battling Monkeys。
这个站点完全由 Flash 生成,不幸的是这意味着搜索引擎不能索引任何文本内容,甚至是各个游戏的链接。
没有 HTML 文本,网页会在搜索结果中的排名将非常低。
使用 SEO 工具来反复检查页面上的文本内容对搜索引擎的可见性是明智之举。这同样适用于图片、链接。
2. 可被爬取的链接结构
搜索引擎需要看到页面的内容才能将它们解析到海量的基于关键字的索引中去,同理,它们也需要知道链接来首先找到内容。 可被爬取的链接结构——拥有让爬虫可以浏览网站的路径——对找到网站的所有页面至关重要。 成百上千的网站在构建导航和过程中错误地使用搜索引擎无法感知的结构,对搜索引擎索引页面造成障碍。
接下来,我们将演示问题是如何发生的:

上述的示例,Google 的爬虫已经触达了页面 A,并且看到指向页面 B 和 E 的链接。 但是,即使 C 和 D 是这个网站重要的页面,爬虫也没有办法触达到他们(甚至不知道它们的存在)。 这是因为没有直接的,可被爬取的链接指向 C 和 D。从 Google 的角度上说,它们并不存在。 优质的内容,良好的关键词定位,聪明的营销,但如果爬虫在一开始就无法触达你的页面,这些东西不会有任何效果。
2.1 解剖链接

链接标签可以包含图片,文本和其它可提供给用户点击区域的对象。
这些链接是原始的互联网导航元素,俗称:超链接。
在上面的插图中:<a 标识链接的开始,链接转介的地址告诉浏览器(包括搜索引擎)这个链接指向哪里。
这个例子中:URL http://www.jonwye.com 被引用。
接下来,链接对用户的可视化部分,称为 “锚文本” 的内容,在 SEO 的世界中描述了这个链接指向的页面:
被指向的页面,”Jon Wye’s Custom Designed Belts” 描述的是关于 Jon Wye 制作的定制款皮带。
最后是 </a> 标签标识链接的结束,用于限制链接文本并防止链接额外包括页面上其他元素。
这是绝大多数链接的基本格式,能够很好地被搜索引擎理解。 爬虫可以将这个链接添加到搜索引擎的链接网络中。 用于计算,与搜索查询无关的的变量(比如 Google 的 PageRank 方法),根据他来创建被链接页面的索引。
2.2 页面不可访问的其他原因
- 需要提交的表单 如果你需要用户完成一个在线表单才能访问具体的的内容,搜索引擎根本没有机会看到这些被保护的页面。 表单可能是一个密码保护的登陆,也可以是一个撑满网页的调查问卷。 无论是哪种情况,爬虫不会尝试提交这些表单,所以任何内容或者链接都不会对爬虫可见。
- 在搜索引擎无法解析的 JS 中的链接 如果你用 JS 替代这些链接,你可能会发现搜索引擎要么不去爬取,要么给这些置于 JS 中的链接很低的权重。 如果你想要爬虫来爬取,标准的 HTML 链接应该替换 JS (或者伴随着它)。
- 链接指向的页面被 Meta Robots 标签或者 robots.txt 阻塞 Meta Robots 标签和 robots.txt 文件都是站长用来限制爬虫的访问。 许多站长使用他们来防止流氓机器人的爬取,但是不经意间阻塞了搜索引擎的爬取。
- Frames or iframes 技术上,frames 和 iframe 里的链接都是可以爬取的,但两者在搜索引擎组织和追踪的时候会出现结构上的问题。 除非你在技术上非常清楚搜索引擎在索引和追钟 frames 里的链接的时候是如何处理的,否则最好避免它们。
- 爬虫不会使用搜索表单 虽然这与上述形式上的警告直接相关,但这是一个常见的问题,值得一提。 有时站长相信如果他们在网站上放一个搜索框,搜索引擎能够发现用户搜索的内容。 不幸的是,爬虫不能会执行搜索来找寻找内容,这导致大量的网页无法触达,直到爬虫爬取过的某个页面有一个链接指向它。
- 在 Flash,Java和其他插件中的链接 嵌入在 Juggling Panda 网站(上面的示例) 中的链接,是非常好的例子。 虽然十几只熊猫,还有链接在页面上列出来,但是没有爬虫能够通过网站的链接结构触达到他们,网站会对搜索引擎隐藏它们。
- 页面上有成百上千的链接 搜索引擎不会在一个页面上爬取这么多链接。 这个限制对于减少垃圾信息和维护排名很有必要。 有几百个链接的页面存在一个也不被搜索引擎爬取的风险。
如果你能避免这些陷阱,你将会有一个清晰,可被爬取的 HTML 链接,能让爬虫非常容易地访问你的内容页面。
3. rel="nofollow"
rel="nofollow" 可以用在以下几种语法中:
3.1 <a href="https://moz.com" rel="nofollow">Lousy Punks!</a>
链接有很多属性。但搜索引擎几乎忽视所有,有一个重要的 rel="nofollow" 属性例外。
上面的例子,添加了 rel="nofollow" 的链接告诉搜索引擎,网站的站长不想这个链接被搜索引擎解释成目标页面的宣传。
“不要追踪”,就字面上来说,命令搜索引擎不要爬取这个链接指向的页面。
nofollow 标签是一种帮助搜索引擎停止爬取自动生成的博客评论,留言板,以及其他方式注入的垃圾链接。
但是已经演变成一种告诉搜索引擎区别需要被忽略的链接的方式。
被标记为 nofollow 的链接在不同的搜索引擎里的表现会稍微有点不太一样,但是它们肯定没有正常的链接权重高。
3.2 nofollow 链接不好吗?
虽然他们没有正常连接的权重高,nofollow 链接是链接多样化里正常的一部分。
一个有很多链接指向的网站会积累很多 nofollow 链接,但这不是一件坏事。
事实上,Moz 的排名因子展示了高排名的网站更倾向于有高比例的入站 nofollow 链接。
3.3 Google
Google 表示在大部分情况下, 他们不会跟踪 nofollow 链接,这些链接也不会影响 PageRank 中锚文本的值。 本质上,nofollow 链接会导致 Google 丢弃链接的目标页面。 nofollow 链接的权重值为 0,并被转换为 HTML 文本(就像链接不存在一样)。 尽管如此,许多站长相信即使 nofollow 链接来自一个高权威的网站,比如 Wikipedia 能被当成一种信任度的标识。
3.4 Bing & Yahoo!
必应,向雅虎提供搜索结果的厂商,也声明他们不会在链接网络中包含 nofollow 链接, 虽然他们也用 nofollow 链接来当作发现新页面的一种方式。 当他们追踪链接的时候,不会使用他们来计算排名。
4. 关键词使用和定位
关键字是处理搜索的关键步骤。它们构成了查询和语言。 事实上,所有信息提取的科学(包括基于 web 的搜索引擎 Google )都是基于关键字。 当搜索引擎爬取和索引网页,它会在基于关键字的索引中跟踪这些页面,而不是在 1 个数据库里存储 250 亿个页面。 采用数百万个更小的数据库,每个以某个关键字和短语为中心,这样的搜索引擎才有可能在秒级完成信息提取。
显而易见,如果你想要页面有机会在 “dog” 的搜索结果里排名靠前,让 “dog” 成为文档可爬取部分是明智之举。
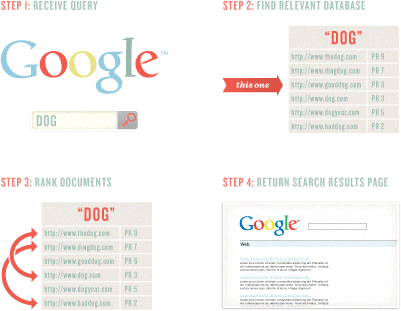
4.1 关键字控制
关键字决定了我们如何传达搜索意图,如何与搜索引擎交互。 当我们输入搜索的词汇时,搜索引擎根据我们输入的词汇来匹配网页。 词语的顺序,拼写,发音,还有大小写作为额外的信息来帮助搜索引擎提取正确的页面并排序。
搜索引擎会测量关键字如何在页面上被使用来帮助决定某个文档对于查询的相关性如何。
最佳优化原则其中之一,就是确保你想要排名靠前的关键字在内容的:标题,内容和 metadata 中都出现。
通常来说,当你的关键词越具体,就缩小了搜索的查询结果集,并且提高获取更高排名的机会。 这个地图形象的表达了相关性的对比:宽泛的关键词 “书籍” 和具体的标题 “双城记”。 广义的术语包含了一大堆结果,而具体的关键词则大量地减少结果数量。

4.2 关键词滥用
自从搜索出现以来,人们在错误的指引下尝试滥用关键词来左右搜索引擎。 包括在文本,URL,meta 标签,链接中堆砌关键词。 不幸的是,这种技巧几乎对你网站的 SEO 更有害。
在早年,搜索引擎把关键词使用作为主要的相关性判断依据,而不管关键词如何被使用。 现在,尽管搜索引擎仍然不能像人类一样理解文本表达的意义,但机器学习的使用让它们更靠近这个目标。
使用关键词的最佳实践就是尽量自然,并附带一点战略性。 如果你的目标关键短语是 “埃菲尔铁塔” 那么你需要自然地把它包含在内容中,比如埃菲尔铁塔的历史,甚至是推荐巴黎饭店。 另一方面,如果你只是简单地突出关键字,而使用了不相关的内容,你对排名第努力就会变成一场持久的逆流战争。
使用关键字的意义不在于对所有的关键字排名靠前,而是当人们搜索你的站点有提供内容的时候能够排名靠前。
4.3 关键词密度神话
关键词密度不是现代排名算法的一部分,如同 Edel Garcia 博士发表的没有意义的关键词密度
如果两个文档 D1,D2 包含 1000 个词项(l=1000),并且重复某个关键词 20 遍(tf=20), 关键词密度分析器会告诉你两个文档的关键词密度(KD)是 20 / 1000 = 0.02。 等价的关键词密度会出现在 tf = 10 并且 l = 500 的文档中。 最终关键词分析器无法判断哪一篇文档的相关性更高。 密度分析器或者关键词比例无法告诉我们:
- 关键词在文档中的相对距离(邻近值)
- 关键词出现在文档中的位置(分布)
- 互相被引用的频率(共生性)
- 文档的内容主题,分主题
结论:关键词密度是脱离内容,质量,语义和相关性的。
那么优化过的的页面的关键词密度应该看上去如何呢?一个经过优化的 “running shoes” 的页面长这样:

你可以从这篇文章,获取更多的页面优化信息
5. 页面优化
关键词使用和定位仍然是搜索引擎排名算法的一部分,我们可以在关键字使用上采用有效的技术来帮助创建良好优化的页面。 在 Moz ,我们从事了很多测试并且得出一些经验。 当对你的网站使用这些技术的时候,我们推荐如下流程:
- 在
title标签至少出现一次。尽可能保证关键词短语和title标签的起始部分一致。 更多关于titile标签的内容会在后面提到。 - 在页面的顶部的显著位置出现一次。
- 在
body部分至少出现两三次,包括 “变体”。如果页面上有很多文本内容,也许需要更多的次数。 你可能会发现多次使用关键词有额外的价值,但就我们看来,添加更多的词项或者短语对排序影响极少。 - 至少出现在 img 标签的
alt属性中一次。这不但有用于网页搜索,更有益于图片搜索。 偶尔会带来有价值的流量。 - 至少在 URL 出现一次。关于 URL 的规则会在后面详细讨论。
- 至少一次在 meta description 标签中。注意 meta description 标签不会对搜索引擎排序有用, 但是会帮助用户在搜索结果页面阅读结果的时候派上用场。 因为 meta description 会被搜索引擎作为摘要来描述页面。
- 正常情况下,不要使用关键字作为锚文本链接到其他页面上,这种做法称为关键字互食。
6. title 标签
一个页面的 title 元素必须要准确,精确描述页面的内容。这无论对于搜索引擎还是用户都很重要。
因为 title 标签是 SEO 一个如此重要的部分,接下来关于 title 的最佳实践影响都不及它。
下面的推荐做法包含为 SEO 和可用性的优化 title 标签的重要步骤。
6.1 小心长度
搜索引擎在搜索结果页面只展现 title 标签最开始的 65-75 1 个字符,之后的内容用省略号代替。
这同样是一个在社交媒体网站上较为普通的限制。坚持这些限制是明智之举。
然而,如果你定位多个关键词(或者是定位一个特别长的关键词短语),让它们保持在 title 标签中对于排名来说必要的,建议你使用较长的 title。
6.2 将重要的关键词放置在页面前部
title 中的关键词越靠前,他们对于排序来说就越有用,一个用户点击它的概率也越高。
6.3 包含商标
在 Moz,我们热衷于在每个 title 标签加上商标,这有助于增加商标的知名度,
并为喜欢或者熟悉我们的用户创造一个更高的点击通过率。
有时候,把你的商标放在 title 的最左部是有意义的,比如在网站首页。
虽然把词汇放在 title 的最左可以获得更高的权重,但是别忘了你是在为什么而排名。
6.4 考虑可读性和情感激励
title 标签应该具有描述性并且可读的。title 标签作为一个新用户的第一交互元素,应该传达正向的情感。
构造一个引人入胜的 title 标签会帮助你抓住用户的注意力,吸引更多的用户来你的网站。
这说明,SEO 不仅强调关键词的使用优化和策略,也注重用户体验。
|
|
|
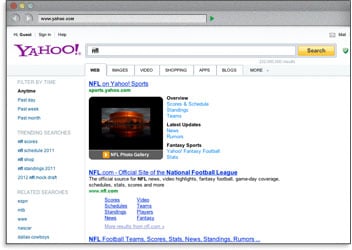
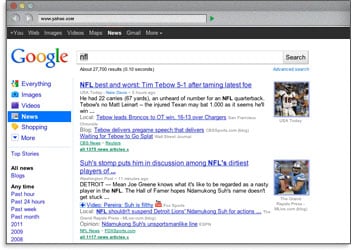
| 任何页面的 title 标签出现在浏览器的顶部,并且当页面的内容被分享在社交网站上的时候,它作为标题出现。 | 在 title 标签中使用关键字,意味着如果有用户搜索这些关键字,搜索引擎可以在搜索结果页面加粗这些词项。这有助于可见性和更高的点击通过率。 | 最后一个使用描述性,带关键字的 title 标签的重要原因是搜索引擎排名。 在 Moz 两年一次的 SEO 行业领先者调查中,94% 的参与者表示在 title 标签上使用关键词是获取高排名的最重要手段。 |
7. Meta 标签
meta 标签一开始倾向于作为一个站点的内容代理来使用。几种基本的 meta 标签列举如下:
7.1 Meta Robots
meta robots 可以以页面为单位来控制搜索引擎的爬取(对大多数引擎来说)。
index/noindex告诉搜索引擎这个页面是否可以被爬取并保存到搜索引擎的索引中。 如果你使用noindex这个页面就会被索引排除在外。默认情况下,搜索引擎假设他们可以索引所有的页面, 所以index这个值通常是没有必要的。follow/nofollow告诉搜索引擎这些链接(本页上的)是否需要被爬取。 如果设置了nofollow,搜索引擎会在发现页面、排名上忽视这些链接(本页上的)。 默认情况下是follow- 例如:
<META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW"> - 没有办法来限制搜索引擎生成页面副本到缓存中。默认情况下,搜索引擎会维护所有已经被索引的页面的可见部分的副本。 这些副本可以在搜索结果页面通过缓存链接来访问。
- 没有摘要可以让搜索引擎意识到在结果页上,应该避免展示被索引页面上靠近
title和 URL 的描述性区域。 noodp/noydir是用来告诉搜索引擎不要从 DMOZ 或者雅虎字典上抓取关于某个页面的描述摘要,在搜索结果页显示。
X-Robots-Tag 是用来达成同样目的的 HTTP Header。 它通常用在非 html 文件上达到相同的效果,比如图片文件。
7.2 Meta Description
meta description 用来简短地描述页面内容。 搜索引擎不会使用在这个标签中的关键词和短语排序。 但是 meta description 是搜索结果页中展现的文本摘要的主要信息源。
meta description 发挥着广告副本的做用,从结果中将读者吸引到你的网站。
是搜索营销中重要的一部分。
用重要的关键字(注意 Google 如何呈现 description)精心撰写一段可读的,引人注目的描述文字,可以帮助你吸引到更多的用户。
meta description 可以有人以长短,但是搜索引擎通常会截断在 160 2 个字符以内,所以最好把长度控制在这之内。
如果缺少 meta description,搜索引擎会从页面元素上截取一段作为它来使用。对于那些目标多个关键词的页面来说,这是一种非常有效的策略。
7.3 不太重要的 meta 标签
meta keywords: 在 SEO 上,它不再像以前那么有价值。SearchEnginLand 发表的文章做了说明。
Meta Refresh, Meta Revisit-after, Meta Content-type 还有其他标签,虽然这些标签对 SEO 有用,
但是处理它们不太重要,我们会在 Google Search Console 帮助 里详细讨论。
8. URL 结构
URL ——文档在互联网上的地址—— 对搜索引擎来说具有很高的价值。他们在多个重要的地方都会出现。

|

|
|
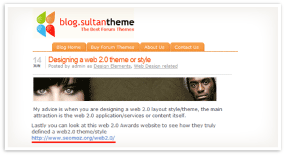
| 因为搜索引擎在结果上展示 URL,所以 URL 会影响点击通过率和可见性。 URL 也会在文档排名中使用,名字包含查询词项的页面会因为使用合理、描述性的关键词而获益。 | URL 会出现在浏览器的地址栏里,虽然这对搜索引擎几乎没有以影响,但是差的 URL 结构可能导致不好的用户体验。 | 上面的 URL 作为锚文本出现在这篇博文中。 |
8.1 如何构建 URL
-
使用同理心 把你自己当成用户,然后看看这个 URL 。 如果你能很容易就推断出你期望在页面上出现的内容,你的 URL 就是合理描述的。 你不需要说明 URL 中的每个细节,但粗略的想法是一个好的起点。
-
越短越好 尽管 URL 的描述性很重要,但精简长度和斜杠让你的 URL 在邮件、博客、文本消息易于复制粘贴, 对所有搜索引擎都全部可见。
-
关键字很重要(但过度使用就危险) 如果你的页面定位在一个词项或者短语,确保在 URL 中包含它。 但是不要为了 SEO 在 URL 中堆砌多个关键词;过度使用会导致 URL 降低可信度并触发垃圾过滤器。
-
静态化 最好的 URL 是人类可读的,不会充斥着太多参数,数字,符号。 使用 Apache 的 mod_rewrite 或者 Microsoft 的 ISAPI_rewrite 技术可以轻松地把类似于这样的:
https://moz.com/blog?id=123的 URL 转换成另一种可读的静态形式:https://moz.com/blog/google-fresh-factor。 在 URL 中的每一个动态参数都会减低全局的排名和索引。 -
使用中划线分割单词 并不是所有的 web 应用都能准确地翻译诸如
_,+,%20这样的分隔符,所以我们用中划线来分隔单词。
9. 标准化和内容重复
9.1 引子
内容重复 算得上是网站最让人苦恼的问题之一。 在过去的几年里,搜索引擎降低重复页面的排名来减少搜索结果中出现重复的概率。
当不同的 URL 出现重复的内容的时候,标准化出现了。 在现代 CMS 系统中,内容重复很常见。 比如,你可能提供一个正常的页面和一个打印优化的页面。 重复的内容甚至出现在多个站点上。对搜索引擎来说,这抛出了一个问题:哪个版本的内容它们应该呈现给用户呢? 在 SEO 的圈子里,这个问题通常指内容重复

|

|

|
| 搜索引擎对同一份素材的多个版本略显挑剔。为了达到最好的搜索体验,它们通常不会展现多个重复的结果。 而是选择一个看起来最原始的那一份。结果是所有的重复内容都会得到比正常低的排名。 | 标准化是每个独立的内容,有且仅有一个 URL 的组织内容的方式。 如果你有同一份内容的多个版本,你可能会面临哪一个对搜索引擎来说才是正确的场景。 | 如果站长用 `301 重定向` 来修改这三个页面,让它们指向一个新的 URL,搜索引擎就会在这个站点上找到一个更匹配的页面。 |
当多个竞争排名的页面结合成一个页面,它们不仅结束了互相竞争,并且创建一个全局上相关性更高,而且更热门的页面。 这会正向地影响你在搜索引擎中的排名。
9.2 拯救者: canonical 标签
搜索引擎的另一个选择称为:Canonical URL 标签, 是另一种解决站内重复内容的方案。 也可以用于不同站点,从一个域名的 URL 指向另一个域名的 URL。
在包含重复内容的页面上使用 canonical 标签。目标指向的就是你想要排名的页面。
9.3 内部工作
<link rel="canonical" href="https://moz.com/blog"/>
这告诉搜索引擎,这个页面应该被作为这个 URL 的的副本,所有链接、内容的指标都应该参照那个 URL。
从 SEO 的角度上来说,canonical 标签有点类似于 301 重定向。本质上,它们都告诉搜索引擎
多个页面应该被当成一个,但不会重定向用户到新的 URL 上。
这会有助于减少开发人员的痛苦。
更多关于重复内容的信息,请参考Dr. Pete 的这篇文章
10. 富摘要
有注意到搜索引擎结果页上的 5 星等级吗?搜索引擎有几率会从网页上嵌入的富摘要获取这样的信息。 富摘要是一种结构化的数据,允许站长通过搜索引擎的方式来标记内容。
虽然使用富摘要和结构化数据对搜索引擎友好的设计来说不是必要的。但是它越来越受到站长的喜爱,某些条件下会从 SEO 获益。
结构化的数据意味着添加标签到你的内容中,让搜索引擎容易识别内容的类型。Schema.org 提供一些能获益的数据例子, 包括:人、产品、评论、生意、配方、事件。
通常,搜索引擎在搜索结果中包含一些结构化的数据,例如用户评论或者作者信息。 有很多不错的在线资料可以学习富摘要,包括: Schema.org, Google’s Rich Snippet Testing Tool, 还有使用 MozBar.
10.1 示例
比如你想要在博客里宣布开一个 SEO 的研讨议。正常的 HTML 代码可能如下:
<div>
SEO Conference<br/>
Learn about SEO from experts in the field.<br/>
Event date:<br/>
May 8, 7:30pm
</div>现在,通过结构化数据,你可以告诉搜索引擎更多关于数据类型的信息。结果可能看起来像下面这样:
<div itemscope itemtype="http://schema.org/Event">
<div itemprop="name">SEO Conference</div>
<span itemprop="description">Learn about SEO from experts in the field.</span>
Event date:
<time itemprop="startDate" datetime="2012-05-08T19:30">May 8, 7:30pm</time>
</div>11. 保护站点荣誉
11.1 别人如何窃取你的排名
不幸的是,互联网上散落着不择手段地从别的站点拔内容,然后在自己的网站上再度使用(有时候以奇怪的修改方式)以达成自己业务的网站。 这种从他站提取信息并在此发布的行为称为:采集。采集者在搜索引擎排名上做得很优秀,通常超过原站。
当你以任何一种反馈的形式发布内容的时候,比如 RSS 或者 XML 确保 ping 下博库和追踪服务比如(Google, Technorati, Yahoo! 等)。 你可以在它们的网站上直接找到 ping 服务的指令,或者使用像 Pingomatic 这样的服务来自动化这一流程。 如果你的发布软件是定制的,正常情况下最好在发布中包含这一流程。
接下来,你可以用采集者的懒惰来对付他们。大多数采集者在重新发布内容的时候都不会修改内容。 所以包含指向你自己网站的链接,指明你自己发布的问杂货那个,可以保证搜索引擎看到这些回链(说明你的资源可能是最原始的)。 为了达成这个目标,需要使用绝对链接,而不是相对链接。这样的链接:
<a href="../">Home</a>需要被替换成:
<a href="https://moz.com">Home</a>这样,采集者截取你的内容,但是链接仍然指向你的站点。
还有很多进阶的方法来保护防止采集,但是没有一种是万无一失的。 你应该明白,站点的热度和可见性更高,被采集的概率也就越大。 很多时候,你可以忽略这个问题,但是当它变得非常严重,你发现采集者夺走你的流量和排名的时候, 你可以使用法律手段,比如 DMCA 来强制他删除内容。 Moz 的 CEO 在保护线上内容不被偷窃的专题 上提供了一些中肯的建议。
12 脚注
- 1: 发稿时测试:Google、百度 支持的 title 长度在 30 个汉字。
- 2: 发稿时测试:Google 支持的 description 长度在 30 个汉字,不包括图片;百度支持 15 个汉字,但是包括图片。
<<<EOF