分布式系统一致性问题
2020-04-15 [分布式
一致性
]
绝大多数 Web App 通过数据库来保证一致性问题,这在单体的应用架构前提下没有问题。
随着业务发展,系统面临流量的增加、业务膨胀,系统架构不得不从原来的单体向分布式改变,通过数据库 ACID 来保证的一致性也不再适用。
什么是一致性
一致性是指系统从一个正确的状态,迁移到另一个正确的状态。 什么叫正确的状态呢?就是当前的状态满足预定的约束就叫做正确的状态。
比如银行系统,A B 两个账户间转账,A 转给 B 100 元。那么转账之前和转账之后,AB 两个账户的余额之和应该是一样的。
不能出现 A 的账户已经扣了 100,B 的账户没有收到的状态;也不能出现 A 的账户还没扣,B 的账户确加了 100 的状态。
分布式系统
从系统架构层面:可以看看 dubbo 总结出的应用架构演进的路线图:
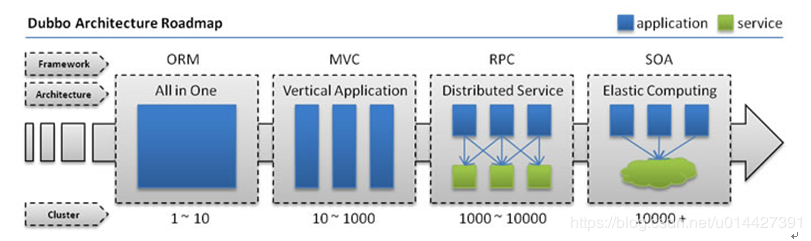
在以 ORM 和 MVC 栈为主的应用中,系统的一致性可以交给数据库去处理,通过在一个 schema(MySQL) 中进行事务来实现。
而随着 RPC、SOA 出现,系统的逻辑拆分成不同模块之间相互调用,以前可以交给数据库做事务来保证一致性,现在已经不行了。
以转账为例:如果是跨行转账,比如上海银行的账户 A 转给重庆银行的账户 B 100 元。上海银行和重庆银行肯定是两套独立的系统,那么一致性该如何保证?
从数据存储的层面:单体应用的数据通常只有一个副本,比如只有一台 server 的 MySQL,只有一个节点的 redis。系统没有数据冗余,一挂全完。
而分布式带来的好处就是通过数据冗余保证可靠性,多副本数据通常散落在不同的 server 上,单个 server/副本 不可用不导致整个系统挂掉。
一个简单的 es 集群
ACID 真的一致吗?
数据库通过事务来保证一致性。业务系统通过将业务锁定在单个 schema 的事务中来保证一致性。
实际上,这个条件是很容易被打破的:
- 当业务发展,需要拆库的时候,单个 schema 被打破。
- 数据库为了应对与日俱增的压力,需要从单 server 切至主从的时候,主从之间也会存在不一致的可能。
CAP 和 BASE
CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),源起计算机科学家埃里克·布鲁尔,他指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency)等同于所有节点访问同一份最新的数据副本
- 可用性(Availability)每次请求都能获取到非错的响应,但是不保证获取的数据为最新数据
- 分区容错性(Partition tolerance) 以实际效果而言,分区相当于对通信的时限要求。 系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
伴随着网络的不确定性,P 作为分布式系统的一大特性无法舍去,分布式系统必须在 A 和 C 中作出选择。
BASE 就是在长期的摸索、实践得出的分布式系统中的 CAP 的最佳实践,始于架构师 Dan Pritchett。
BASE 的核心是确定 C 和 A 的最佳平衡点:即使无法做到强一致性(CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性。
- Basically available 出现故障的时候,允许损失部分可用性,即,保证核心可用。
- Soft state 软状态:允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
- Eventual Consitency 系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
答案
对于开发人员而言,针对一致性的强弱,保证一致性的手段也不同。
强一致性:
XA 事务
xa 分为内部 xa 和外部 xa。内部 xa 是指在同一个 server 上进行,跨 schema 的事务;外部 xa 是指跨多个数据库 server 实例。
本质上,xa 是通过 transaction manager(协调者) 和 resource manager(参与者)实现的两段提交:
![]()
xa 事务阻塞时间长,效率低。在第二阶段,由 tx manager 发起的 commit 请求如果由于网络丢失,会出现不一致的情况。
最终一致性:
TCC 事务
Try-Confirm-Cancel。每个参与者需要支持 Try, Confirm 和 Cancel 三个逻辑分支。
然后交给 tcc 框架执行,框架负责协调,根据每个参与者的执行情况来决定事务提交或者回滚。
还是举转账的例子,比如是从余额 200 的银行卡转 100 元到余额为 0 的支付宝账户里,对应的参与者称为 BankService 和 AlipayService。
那么,会有:
![]()
tcc 首先会让参与者 try,执行诸如检查是否满足条件,设置中间状态等工作;然后发起 confirm,如果每个参与者都成功 confirm,则事务执行成功。如果有任一参与者 confirm 失败,就挨个儿执行 cancel,还原至事务进行前的状态,保证一致性。
注意, tcc 在 confirm 和 cancel 的过程中会有重试机制,也就是说,需要在业务上做到 confirm 和 cancel 的幂等性。
分布式系统通过网络实现跨机器互相调用,不能保证 confirm 和 cancel 的调用次数是 1。
使用 tcc 事务框架有一个潜在的前提条件,就是多个模块之间必须统一实现语言。如果模块跨语言,就需要一款支持多语言的 tcc 框架。
再比如在和第三方系统交互的时候,tcc 也难以派上用场。比如你是某银行系统的开发人员,现在需要将系统和支付宝打通,实现银行账户和支付宝间的转账等功能,那肯定不能依靠 tcc 了。
支付宝提供的接口一般为 http 接口,那怎么办呢?
本地消息列表
本地消息列表的核心是将 1 个 “大” 事务转换成多个本地 “小” 事务,在小事务中附加消息的处理。 消息有点类似于一条条操作日志,这些日志可能会有一系列的状态。
当本地事务(try)执行后,入库一条消息,并且通知外部系统。 通知外部系统这个过程可能会失败,所以必须要有重试机制。 当外部系统处理成功后,再通知回自己,自己执行提交逻辑(confirm)。 外部系统处理失败也一样需要通知自己,此时再执行回滚逻辑(cancel)。
以本地银行系统向外部支付宝系统转账为例:
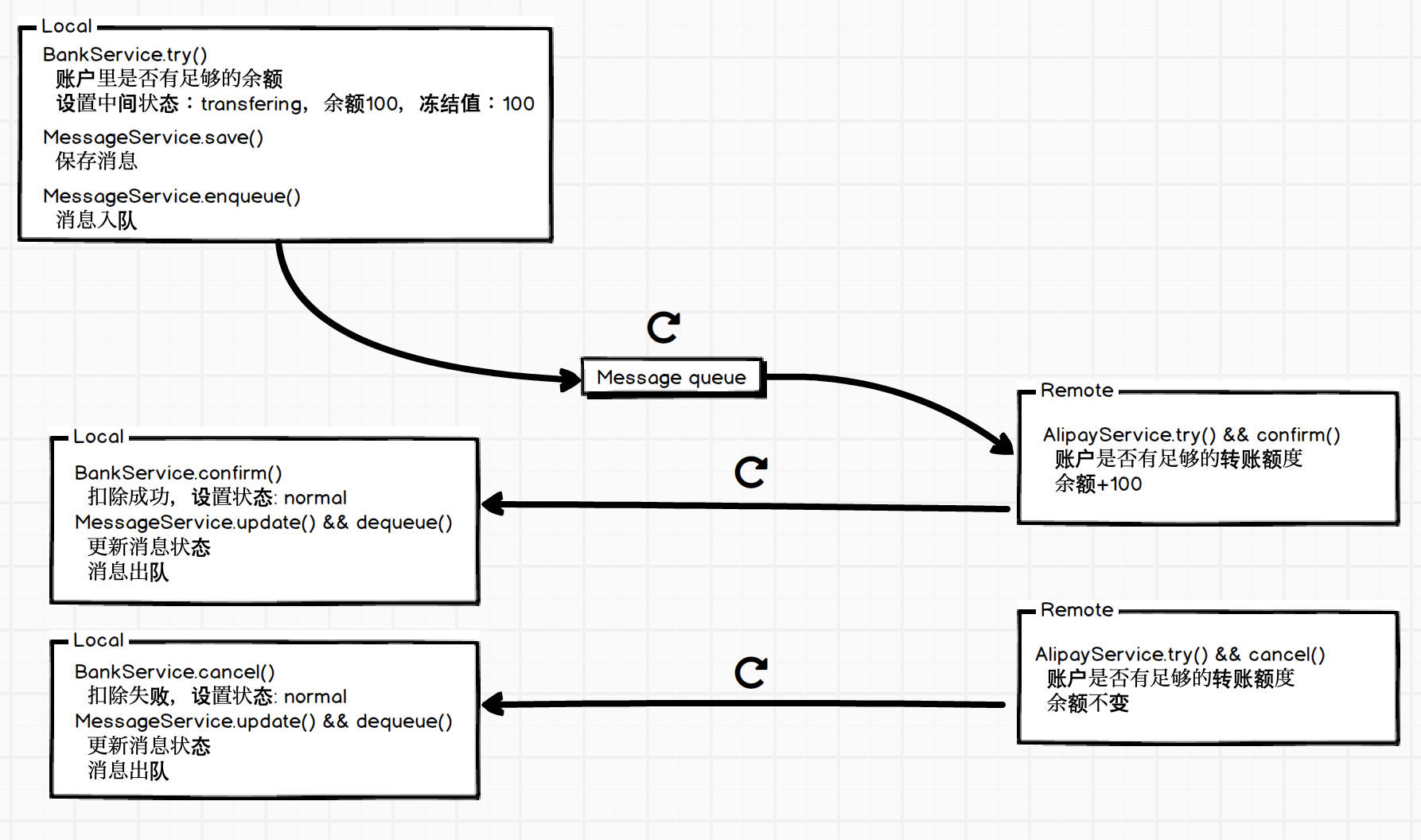
首先本地事务发起转账逻辑,类似于 tcc 做一个 try 操作,然后将消息入库;
消息入库后,由另外一个任务,不停的轮询本地未得到 remote 系统回应的消息,并且执行发送逻辑,发送失败时,需要重试;
当 remote 系统执行后,根据结果再通知回 local 系统,local 系统修改消息的状态,并更新账户余额。
当然,这其中少不了分布式锁的并发控制和幂等性处理。
本地消息列表作为最灵活、适用性最广,也是性能最佳的方案,但是也考验系统设计。
MQ 事务
部分消息队列中间价支持事务消息事务。如 RabbitMQ、RocketMQ。
![]()
mq 事务大致可以理解成,mq 对本地消息列表做了一层封装。消息入队这个操作被分解成两个步骤。
业务只需要做 try 和 message enqueue。remote 系统作为消息队列的下游,它只负责接受消息并反馈 ack 。同时,还免去了本地消息列表中的无限轮询需要发送的消息的任务,简化了不少业务操作。
需要注意:下游服务返回的 ack 并不等同于业务上的处理成功。在下游处理失败时,仍然要通知上游。
具体实现可以对应逻辑分支再开辟两个 topic,上游作为消费者去监听下游的业务反馈。
小结
可以看到,一旦进入的分布式系统的时代,为了达成一致性,系统复杂度提升不少。
众多达成分布式一致性手段中,本地消息列表历史悠久,灵活,适应性,但是对开发者要求也最高:业务幂等、重试限制、并发控制三者缺一不可。
其次是 MQ 事务,为开发省不少力气。老牌消息队列 RabbitMQ 的 client 的支持还是不错的。
再者 TCC。提出一个非分之想:是否可以基于 gRPC ,出一个跨语言的 TCC 事务框架。
除了上述解决方案,另有蚂蚁金服的黑科技 seata, DTS 可以摸索。
_REF
<<<EOF