凑近一点看 cpu
2020-06-04 [cpu
超线程
亲和力
numa
]
cpu 是普通 pc 上最昂贵的部件,系统如何使用它?我们经常在电脑参数上看到的 N 核 M 线程到底是指的什么?X86 和 AMD 又是什么?
来,让我们凑近一点看看这家伙。
cpu 基本构造
cpu 通过插槽(socket)安装在 pc 主板上,与台式机不同的是,笔记本的 cpu 大都焊接在主板上的,不可更换。 作为电脑的核心元件,cpu 标志着电脑处理、计算的能力。
打开台式机箱,就能看到它:

cpu 有以下几个核心指标/参数,其中一些也许你已经在逛电脑城的时候耳熟能详了。
cpu 字长
是单位时间内 cpu 能处理的二进制数据的位数。这里的单位时间是 cpu 内的时钟周期,是 cpu 执行动作的最小时间单位,而不是指 1s。
我们只能说 cpu 执行某个动作需要 1 个时钟周期,两个时钟周期,绝对不会有 1.5 个时钟周期。
内频(主频)
内部工作频率简称内频,它的另一个名字叫做主频,单位是赫兹(Hz)。cpu 的内频或者说主频的定义为 cpu 内数字脉冲信号震荡的速度。
简单来说就是我们说的时钟周期和秒的对应,cpu 一秒内有几个时钟周期主频就是多少赫兹,比如 2.6GHz 表示 1 秒内有 2,600,000,000 个时钟周期。
外频
外部工作频率简称外频。外频是由主板为 cpu 提供的基准时钟频率。 简单来说就是主版规定 cpu 在 1 秒内对外进行数据交换的次数。 在早期 cpu 的主频和主板上其他部件差距不大所以外频通常和内频也就是主频是一样的。
后来随着技术的提高,cpu 主频远远超过了其他硬件的频率,所以就引用了倍频来协调二者之间的差距,公式:内频(主频)= 外频 × 倍频。 简单的说就是主板时钟走一次 cpu 内部时钟就走 N 次,这个 N 就是倍频的数了。现代cpu 的倍频最高已经高到了40+。
cpu 核心数
cpu 核心数代表该 cpu 在某一时刻运行的线程数。单核时代,在某一时刻,cpu 上运行的线程数 = 1,多核架构增加了 cpu 并行处理能力。
cpu 线程数
上述 cpu 核心数既然已经表示线程数量,为什么还要再来一个线程数?
因为相比于计算机其它元件,cpu 计算速度实在太快了,即使同一时刻赋予一个线程运行,从 cpu 的时钟周期看,周期里仍有不少空闲的“碎片”,有没有可能把这些碎片都利用呢?
intel 提出超线程概念就是将一个物理核心模拟成两个逻辑核心,使得 1 个核心在同一时刻,从用户的角度上看,有两个线程在并行。
cache 高速缓存
cache 高速缓存是用来调节 cpu 和主存之间读写速度差别的,注意是主存(主存指的是能被 cpu 直接访问到的存储器)。 cache 的作用是提前预读内存上的内容,这样 cpu 就不用直接访问内存而是直接从 cache 上读取信息。
比如我们编写一个 java 程序中用到了数组,由于数组是一种紧凑的数据结构,程序会提前尝试将数组的数据加载到 cache 里,这样再次访问的时候加快了访问速度。
由于 cache 性能远远高于内存,所以对 cpu 性能影响非常大。cpu 上的缓存大致可以分为 L1,L2 和 L3 三层。
L1 最靠近 cpu,访问速度最快,容量也最小;当查询 L1 miss 的时候,会查询 L2,以此类推,当 L3 miss 的时候,再访问主存。
地址总线
地址总线负责 cpu 的主存寻址,地址总线有多少位决定了 CPU 最大能使用多少主存(注意是主存)。 这个计算方法很简单,最大主存容量 = 2 的 N 次方,其中 N 是地址总线位数。
如果地址总线是 32 位的那么只能使用 2 的 32 次方也就是 4GB 主存,对于 44 位的地址总线就能使用 16TB 主存了。
值得注意的是地址总线的位数并不一定指的是 cpu 的位数,我们平时说的 32 位 cpu 和 64 位 cpu 指的是 cpu 字长而非地址总线位数。 32 位 cpu 的地址总线通常是 32 位的,但是 64 位 cpu 的地址总线通常也不是 64 位,一般也就是 40 位左右。 即使你使用了地址总线位数超过 32 位的 cpu,那么要想使用超过 4GB 的主存也必须要操作系统支持,支持的方法有两种:1是使用64位操作系统,2是使用32位系统开启物理地址扩展(PAE)。
如果 cpu 本身是 32 位的那么是不可能使用超过 4GB 主存的。
cpu 架构
cpu 架构又叫 cpu 指令集架构(Instruction Set Architecture),又称指令集,可以理解为是一套面向 cpu 硬件的 api。
目前主流的两套架构是以 intel/amd 的 x86 架构,和 arm(公司) 的 arm 架构。
x86 架构以复杂的逻辑电路著称,支持复杂指令集(cisc) ,便于编程,适用广泛。其中根据支持的字长又分为 x86-64、x86-32、x86-16。 arm 架构相对简单,支持精简指令集(risc) ,与硬件耦合度高,功耗低,普遍用在移动设备上:手机、路由器。
以 java 程序为例,我们编写的 .java 文件是源码,通过 javac 编译为 java 字节码之后,交给 jvm 运行。jvm 在运行时再将字节码转换成 cpu 指令,这样操作系统才能执行。
而 java 程序之所以号称 write onece, run anywhere 得益于 jvm 支持全平台。
其它
前端总线(FSB,Front Side Bus)频率在单核时期也是重要指标。总线作为 cpu 对外门户,负责 cpu 和北桥芯片相连,再由北桥作为中转,向图像、内存、南桥芯片通讯。随着多核兴起, QPI(Intel QuickPath Interconnect)、HyperTransport 取代了前端总线。
制作工艺反应 cpu 的精细程度,越是精细,在有限的空间上就能集成越多的电子元件,处理能力也越强。通常听到的 xx 纳米某种程度上反应了工艺精细程度。
在 linux 上看 cpu
在 linux 系统上可以用 lscpu 命令查看 cpu 的基本信息。
输出结果包括:
Architecture: x86_64 # x86 架构 64 位
CPU op-mode(s): 32-bit, 64-bit #
Byte Order: Little Endian #
CPU(s): 32 # 逻辑处理器数量
On-line CPU(s) list: 0-31 # 当前使用中的处理器,id 从 0 开始
Thread(s) per core: 2 # 每个 core 上的线程数
Core(s) per socket: 8 # 每个 cpu 内置的核心数
Socket(s): 2 # 2 个 插槽对应了 2 个物理 cpu
NUMA node(s): 2 # numa 节点数
Vendor ID: GenuineIntel #
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
Stepping: 1
CPU MHz: 1200.000
BogoMIPS: 4194.71
Virtualization: VT-x
L1d cache: 32K # L1 数据存储大小,d: data
L1i cache: 32K # L1 指令存储大小,i: instruction
L2 cache: 256K # L2 缓存大小
L3 cache: 20480K # L3 缓存大小
NUMA node0 CPU(s): 0-7,16-23 # numa 0 节点对应的核心
NUMA node1 CPU(s): 8-15,24-31 # numa 1 节点对应的核心
回想一下 cpu 的基本结构,由于服务器对于处理能力的要求,它的主板上可能存在多个 cpu (相对于普通家用电脑的单 cpu)。
cpu、socket、core 它们三者的关系如下:
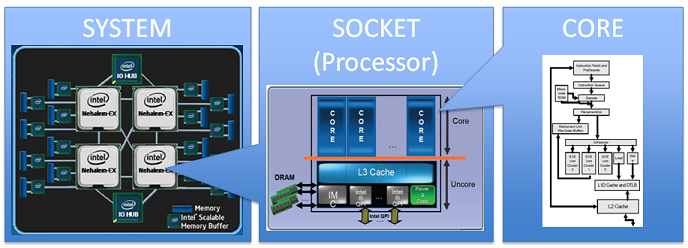
插槽数对应 cpu 数,1 个插槽就是 1 个 cpu。每个 cpu 内部又存在多个物理 core,每个 core 又有可能因为 超线程 可以支持多个线程。
这里最后的线程就是逻辑处理单元,也就是在 top 命令中看到的 cpu 个数,和 cat /proc/cpuinfo 中的 processor 对应。
cpu 亲和力
运行中的进程,通过向操作系统申请资源得以正常运行。cpu 是一种核心计算资源,当它被耗尽时,所有程序都失去响应。windows 上的沙漏,mac os 上的风火轮,大家都不会陌生吧。
操作系统通过调度器(scheduler)来分配 cpu 资源。linux 平台上有如下集中调度器: O1, BFS, CFS。这些调度器都是 linux kernel 的一部分。
cfs 本身功能强大,支持多种策略、参数,应用通过配置,就可以向 os 诉求用自己想要的 cpu 资源。但这样的底层系统调用,仅在 c 语言支持。
其实,当我们有定制应用 cpu 使用的需求时,可以通过指定线程优先级、修改 cpu 亲和力来达成。
cpu 亲和力(cpu affinity) 指的是程序如何关联(绑定) cpu。 该技术基于 对称多处理机操作系统 SMPS(Symmetric Multiprocessor System) 中的 native central queue 调度算法。队列中的每一个任务都有一个标签来指定它们倾向的处理器。在分配处理器的阶段,每个任务就会分配到它们所倾向的处理器上。
也就是说,我们可以绑定某个进程到指定到 cpu 上执行。那么,这样做有什么好处呢?先来看看操作系统为我们提供的默认亲和力是什么样。
通过 taskset 命令,可以查看、设置进程的 cpu 亲和力。
假设某台机器上 cpu 情况如下:
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2 # 可以看到目前操作系统只有两个逻辑 cpu
On-line CPU(s) list: 0,1
Thread(s) per core: 1 # 未开启超线程
Core(s) per socket: 2
...
某 java 进程的 pid 为 7028
# taskset -p 7028
pid 7028's current affinity mask: 3
affinity mask 为 16 进制,3 对应的二进制为:11;也就是 1# cpu 和 0# cpu,对应 top 命令里的 %Cpu1 和 %Cpu0:
top - 01:13:13 up 1053 days, 21:44, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 100 total, 1 running, 99 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.7 us, 1.0 sy, 0.0 ni, 98.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
可以看到系统默认为进程分配的是所有 cpu,也就是说该 java 进程下的线程有可能被打散在 2 个 cpu 上执行。 当系统 cpu 较少的时候,这样的确比较科学,因为正常情况下 1 个 java web 进程里少说有 2、30 个线程在运行,远高于系统 cpu 数量。
而当系统有足够的 cpu 资源的时候,我们更希望提供给进程一些 专用 的 cpu 资源。一方面减少其它进程带来的竞争干扰,还可以减少由于自身线程频繁切换导致的 cache 失效。
修改亲和力也很简单,仍然 taskset 命令。
# 将 7028 进程绑定在 0# cpu 上
# taskset -p 1 7028
小结一下,我们可以通过以下步骤尝试实战:
- 通过应用的业务类型判断是否需要绑定 cpu。诸如计算密集还是 io 密集,线程数量何如,目前吞吐如何等。
- 通过 top 命令观察 cpu 使用情况,如某些物理 core 长期处于空闲状态,可以考虑分配给指定进程。
- 修改亲和力后,对比未修改时的系统指标:吞吐量、QPS、平响。
- 验证指标数据。
NUMA
NUMA 和 SMP
NUMA 和 SMP 是两种 cpu 相关的硬件架构。在 SMP 架构里面,所有的 cpu 争用一个总线来访问所有内存,优点是资源共享,而缺点是总线争用激烈。 随着 PC 服务器上的 cpu 数量变多(不仅仅是cpu核数),总线争用的弊端慢慢越来越明显,于是 Intel 在推出了 NUMA 架构,而 AMD 也推出了基于相同架构的 Opteron cpu。
NUMA 全称叫 (None-uniform Memory Access),它将系统的 cpu、memory 划分为若干个 node,每个 node 同时拥有 cpu 和 mem 两种资源。 在同一个 node 的内存访问称为本地内存,跨 node 的内存称为远程内存。
可以通过 numactl --hardware 查看当前 node 划分情况:
# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1
node 0 size: 3965 MB
node 0 free: 143 MB
node distances:
node 0
0: 10
分配方式
通过 numactl 可以查看当前系统的 numa 信息,为进程分配 numa node。和 taskset 不一样,numactl 不支持热修改,更新配置必须要重启进程。
- 每个进程(或线程)都会从父进程继承 NUMA 策略,并分配有一个优先 node。如果 NUMA 策略允许的话,进程可以调用其他node上的资源。
- NUMA 的 cpu 分配方式有: cpunodebind, physcpubind。 cpunodebind 规定进程运行在某几个 node 之上,而 physcpubind 可以更加精细地规定运行在哪些核上。
- NUMA 的 内存分配方式有: localalloc, preferred, membind, interleave。
- localalloc: 规定进程从当前 node 上请求分配内存,当 node 内存不足时触发 oom 或者 swap。
- preferred: 比较宽松地指定了一个推荐的 node 来获取内存,如果被推荐的 node 上没有足够内存, 进程可以尝试从别的 node 申请内存,当然 distance 越大,访问速度也越慢。
- membind: 可以指定若干个 node,进程只能从这些指定的 node 上请求分配内存。
- interleave: 规定进程从指定的若干个 node 上以 RR(Round Robin 轮询调度)算法交织地请求分配内存。
因为 NUMA 默认的内存分配策略是 localalloc;它优先在进程所在 cpu 的本地内存中分配,会导致 cpu 节点之间内存分配不均衡。 当某个 cpu 节点的内存不足时,会导致 swap/oom 产生,而不是从远程节点申请内存。
而在一些比较重的服务(比如数据库)上使用 numa,如果姿势不对,容易导致异常。
我们可以把一个 numa node 作为一个相对隔离的逻辑硬件环境,将服务绑定在上面运行;而这个服务对 cpu 和 内存的诉求,最好控制在 numa node 容量内。
Examples
评估好我们的应用对资源的使用情况,结合 numactl 提供的分配方式,才可以将应用以 numa node 的方式运行,期待性能上的提升。
# 将 myapplic 绑定在当前 node 中的 0-4# cpu,8-12# cpu 运行
numactl --physcpubind=+0-4,8-12 myapplic arguments
# 指定 database 在申请内存时,以交织模式从所有 node 上申请
numactl --interleave=all bigdatabase arguments
# 指定 process 运行在 node 0 的 cpu 上,内存访问限定在 node 0 和 1 上
numactl --cpunodebind=0 --membind=0,1 process
# 设置 preferred node 为 1# 并查看 numa 状态
numactl --preferred=1 numactl --show
REF
- 前端总线
- 不要完全相信Linux Top:超线程(Hyperthreading)深入浅出
- Hyper-Threading speeds Linux
- CFS description at ibm.com
- Linux 和对称多处理
- NuMA
- Optimizing Applications for NUMA
<<<EOF