Spark 分区数量
2021-02-19 [spark
]
Spark 作为分布式数据处理框架,可以将大数据处理分散到众多廉价 pc 机上,并行执行。
RDD 【Resilient Distributed Datasets】作为 spark 核心基础接口,spark-sql 和 spark-streaming 底层都依赖 rdd。
1 个 rdd 可以分布多台机器上。而在 rdd 背后,是一个个 partition(分区)。
Spark 应用在执行数据操作时,每个物理任务被分配到手、进行处理的数据就是 1 个分区:
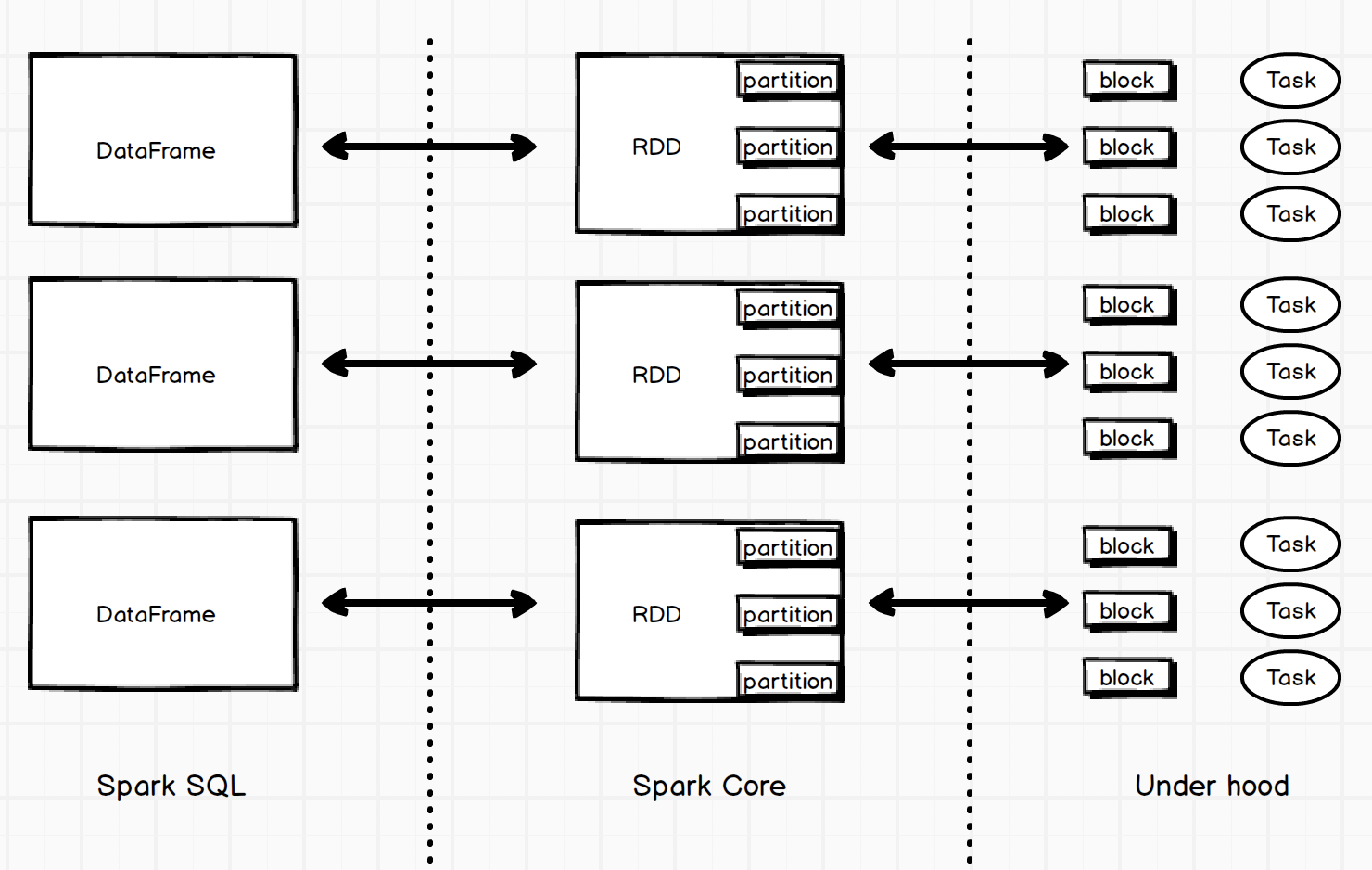
Spark 在计算时称数据为 rdd / partition,在存储和传输的时候称数据为 block。block 和 partition 是 1 对 1 的关系。
Spark rdd 支持如下数据源:
- 并行化集合:通过 spark context 构造,如
sc.parallelize((1, 2, 3, 4, 5, )) - 外部数据:支持本地文件,和所有基于 hdfs 存储的数据源,包括 Cassandra, HBase, Amazon S3, SequenceFiles, 和其它 Hadoop InputFormat。
RDD 分区
spark.default.parallelism
Default number of partitions in RDDs returned by transformations like
join,reduceByKey, andparallelizewhen not set by user.
该参数在 spark 文档上的解释是:rdd 转换操作后返回的 rdd 的默认分区数量。转换操作可以是 join / reduceByKey / parallelize 。其中 join / reduceByKey 都是针对 PairRDD。
当进行分布式的 shuffle 操作时,spark 会先规划好分区,分区数等于父 rdd 分区数的最大值。在诸如进行 parallelize 之类没有父 rdd 的操作时,它的值取决于 cluster manager:
- local mode:本地模式,取决于当前机器节点上可用的核心数,也就是
local[n]中的 n 的值 - mesos fine grained mode: mesos 细粒度模式,等于 8
- other:其它情况,
max(executors * cores, 2)
pyspark 测试:
In [1]: rdd = sc.parallelize(range(100))
In [2]: rdd
Out[2]: PythonRDD[1] at RDD at PythonRDD.scala:53
In [3]: rdd.getNumPartitions()
Out[3]: 16
由于 pyspark 默认是 local[*] 模式,16 是当前电脑核心数。
在加载外部数据源的时候,本地文件和 HDFS 文件的处理不同:
-
本地文件的默认分区算法 math.min(defaultParallelism, 2),其中 defaultParallelism 就是上述配置。
-
hdfs 文件其分区数量可以从
InputFormat.getSplits方法获取。通常每个 partition 对应 1 个 block split。
pyspark 测试本地文件:
In [4]: rdd2 = sc.textFile('/Users/toien/Tools/spark-2.4.5-bin-hadoop2.7/README.md')
In [6]: rdd2.getNumPartitions()
Out[6]: 2
pyspark 测试 hdfs 文件:
In [26]: rdd4 = sc.textFile('hdfs://localhost:9000/input/block-size.txt')
In [27]: rdd4.getNumPartitions()
Out[27]: 2
In [31]: rdd4 = sc.textFile('hdfs://localhost:9000/input/block-size-large.txt')
In [33]: rdd4.getNumPartitions()
Out[33]: 4
测试时发现 hdfs 文件的分区数和预期的不太一样:
- 如果文件大小小于 block 的大小,分区数不会为 1
- 分区数 = block 数量 - 1
> hadoop fsck /input -files -blocks
/input/block-size.txt 6 bytes, 1 block(s): OK
0. BP-1361422327-127.0.0.1-1598448343998:blk_1073742577_1761 len=6 repl=1
/input/block-size-large.txt 543779550 bytes, 5 block(s): OK
0. BP-1361422327-127.0.0.1-1598448343998:blk_1073742578_1762 len=134217728 repl=1
1. BP-1361422327-127.0.0.1-1598448343998:blk_1073742579_1763 len=134217728 repl=1
2. BP-1361422327-127.0.0.1-1598448343998:blk_1073742580_1764 len=134217728 repl=1
3. BP-1361422327-127.0.0.1-1598448343998:blk_1073742581_1765 len=134217728 repl=1
4. BP-1361422327-127.0.0.1-1598448343998:blk_1073742582_1766 len=6908638 repl=1
RDD 分区器
打印上述 rdd4 的分区器,发现竟然是 None:
In [37]: print(rdd4.partitioner)
None
partitioner 为 None 说明 rdd 的分区不是基于数据特征,而是随机分布。
parititioner 通常是针对 键值对 RDD 才有的属性,并不是说有 partition 就一定有 paritioner。
分区逻辑可以由 spark 决定,也可以由外部数据源如 hdfs 决定。如:rdd = sc.textFile("hdfs://.../file.txt", 400),400 是分区数。但这里的 400 个分区是由 Hadoop TextInputFormat 处理,而非 spark。
相比 rdd.repartition() ,这样通常会更快。在真实的生产环境,由于 spark 运行在多台机器的分布式环境中, repartition() 带来的数据混洗 (shuffle) 并不高效。
Spark sql
spark.sql.files.maxPartitionBytes
The maximum number of bytes to pack into a single partition when reading files.
当使用 spark sql 读取非 hdfs 分片数据源时,分区数会受此参数影响。
例如从本地 nd-json 文件中读取数据构造 DataFrame 时,分区大小受它限制。
spark.sql.files.openCostInBytes
The estimated cost to open a file, measured by the number of bytes could be scanned in the same time. This is used when putting multiple files into a partition. It is better to over estimated, then the partitions with small files will be faster than partitions with bigger files (which is scheduled first).
文件的打开成本,也就是说 spark 会将低于此阈值的多个小文件 paritition 合并成单个 partition。将该参数调高会让 spark 调度优先处理小文件构成的分区。
spark.sql.shuffle.partitions
Configures the number of partitions to use when shuffling data for joins or aggregations.
在 DataFrame/DataSet 由于 join / aggregate 而导致 shuffle 发生时,spark 会使用该参数控制 partition 的数量。
NOTE: spark.default.parallelism 这个参数只是针对 rdd 级别的 shuffle 操作才生效,比如 join,reduceByKey。
numPartitions (jdbc)
当通过 jdbc 协议读写数据时,支持的最大分区数。每个 jdbc 分区会使用单独的 jdbc 链接。如果由于数据量太大超过这个限制,spark 会在写入 db 之前调用 coalesce 重新分区。
Spark streaming
streaming 虽然作为实时流数据处理引擎,其底层也是微批(micro-batch),即将一定时间的收集到的数据作为一个 rdd,再进行后续的处理;而非基于数据事件,说白了其实是伪实时。

上面提到的 “一定时间” 在 spark 中叫 batch interval,还有一个参数叫 block interval,指的是在每个 rdd 中,每个 block 的时间范围。

所以,如果每一批次的数据有 N 个 block,那么 N = (batch-interval / block-interval) 。
比如我们将 streaming 的 batchInterval 设为 5s,blockInterval 保持 200ms 的默认值,那么每一批数据:
N = 5s / 200ms = 25 (blocks)
Spark UI
最后来一起看一个 streaming app 的例子,其中某个 job 388580:
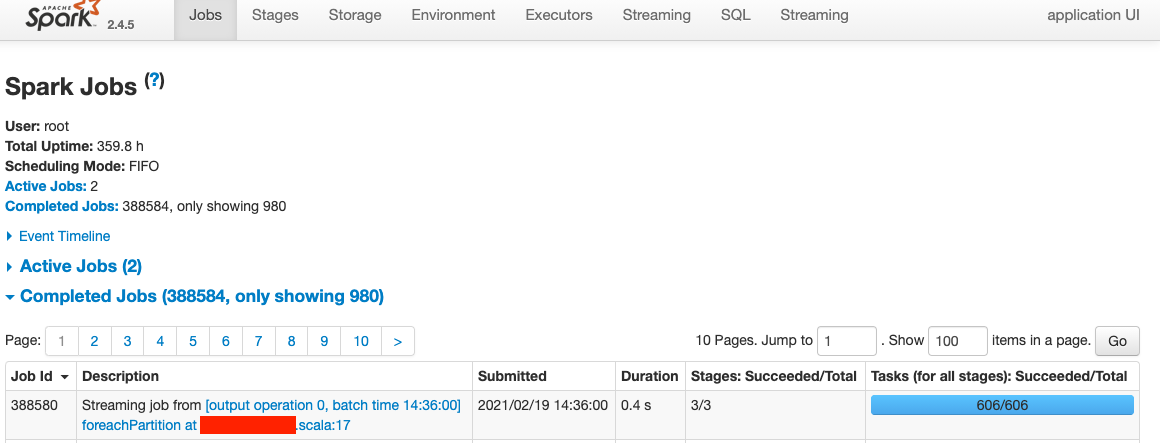
可以看到该 job 一共包含了 606 个 tasks,也就是说一共处理了 606 个 partition。
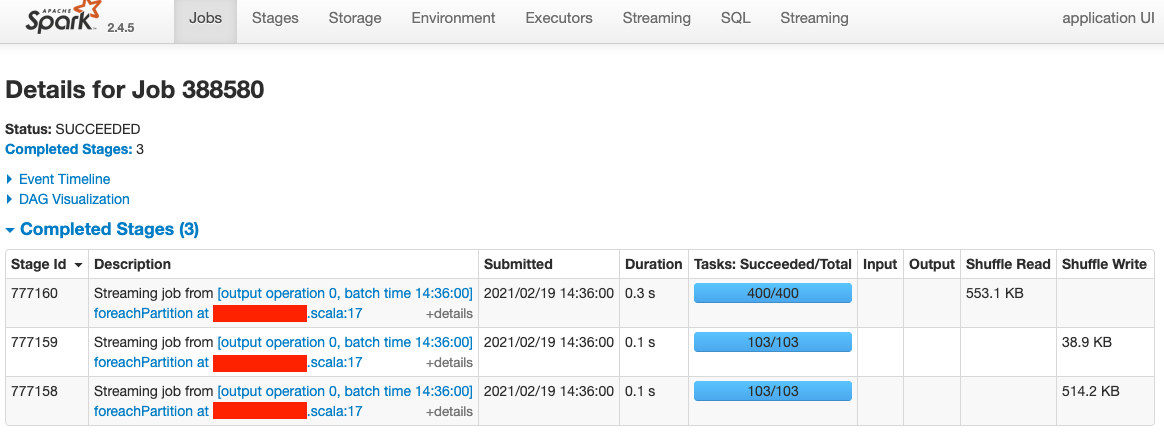
点进去看 job detail,该 job 一共包含 3 个 stage,stage 依次是 777158、777159、777160。
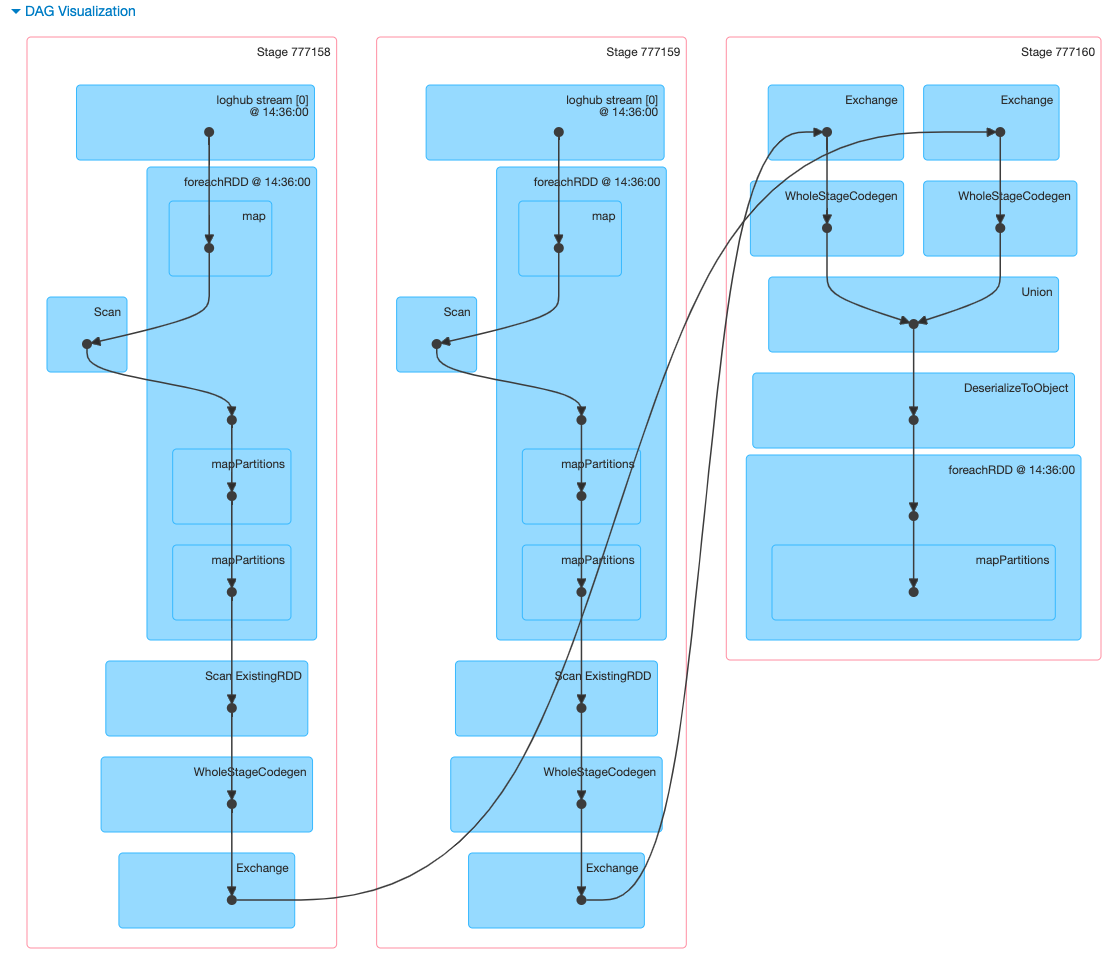
观察 158、159 的 DAG,可以看到是以 loghub stream 为源头,解析成 rdd,然后进行 mapPartitions 操作。每个 stage 包含 103 个 partition(block)。我的参数配置下,N = 30s / 200ms = 150。103 < 150,猜测是由于 loghub sdk 合并了部分较小的 block。
而后的 160 由于存在 sql agg 操作,每个 stage 的 103 blocks => 200 blocks (spark.sql.shuffle.partitions),所以总共是 400 blocks。
sql union 操作并不影响底层 block,只是做了逻辑上的合并,物理数据(block)仍严格遵循血缘关系。
_REF
- 理解 spark 中的 partition 和 block 的关系
- What is the difference between spark.sql.shuffle.partitions and spark.default.parallelism?
- How does Spark partition(ing) work on files in HDFS?
- Spark Streaming – under the hood
<<<EOF