在 Flink 任务中使用动态编译
2023-06-12 [flink
java
dynamic-compile
]
Java 动态编译是一项比较成熟的技术,用于在程序运行期间生成 Class ,为实现业务带来了极大的灵活性。 本文讨论如何在 Flink 任务里使用动态编译,以及遇到的坑。
动态编译
在开始讲动态编译之前,先回忆一下静态编译。
静态编译
- 编写
.java源代码 - 利用 javac 将源代码编译为 class 文件
- 打成可执行 jar 包发布
深入一点上述第 2 步的编译过程,假设现在有一个 HelloWorld.java 代码如下:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
我们现在尝试通过 javac 来编译它, 打开 verbose 日志:
# 已格式化
> javac -verbose HelloWorld.java
[parsing started RegularFileObject[HelloWorld.java]]
[parsing completed 11ms]
[search path for source files: .]
[search path for class files:
${JDK_HOME}/Contents/Home/jre/lib/resources.jar,
${JDK_HOME}/Contents/Home/jre/lib/rt.jar,
${JDK_HOME}/Contents/Home/jre/lib/sunrsasign.jar,
${JDK_HOME}/Contents/Home/jre/lib/jsse.jar,
${JDK_HOME}/Contents/Home/jre/lib/jce.jar,
${JDK_HOME}/Contents/Home/jre/lib/charsets.jar,
${JDK_HOME}/Contents/Home/jre/lib/jfr.jar,
${JDK_HOME}/Contents/Home/jre/classes,
${JDK_HOME}/Contents/Home/jre/lib/ext/sunec.jar,
${JDK_HOME}/Contents/Home/jre/lib/ext/nashorn.jar,
${JDK_HOME}/Contents/Home/jre/lib/ext/cldrdata.jar,
${JDK_HOME}/Contents/Home/jre/lib/ext/jfxrt.jar,
${JDK_HOME}/Contents/Home/jre/lib/ext/dnsns.jar,
${JDK_HOME}/Contents/Home/jre/lib/ext/localedata.jar,
${JDK_HOME}/Contents/Home/jre/lib/ext/sunjce_provider.jar,
${JDK_HOME}/Contents/Home/jre/lib/ext/sunpkcs11.jar,
${JDK_HOME}/Contents/Home/jre/lib/ext/jaccess.jar,
${JDK_HOME}/Contents/Home/jre/lib/ext/zipfs.jar,
.
]
[loading ZipFileIndexFileObject[${JDK_HOME}/Contents/Home/lib/ct.sym(META-INF/sym/rt.jar)]:
java/lang/Object.class,
java/lang/String.class
]
[checking HelloWorld]
[loading ZipFileIndexFileObject[${JDK_HOME}/Contents/Home/lib/ct.sym(META-INF/sym/rt.jar)]:
java/io/Serializable.class,
java/lang/AutoCloseable.class,
java/lang/Byte.class,
java/lang/Character.class,
java/lang/Short.class,
java/lang/Long.class,
java/lang/Float.class,
java/lang/Integer.class,
java/lang/Double.class,
java/lang/Boolean.class,
java/lang/Void.class,
java/lang/System.class,
java/io/PrintStream.class,
java/lang/Appendable.class,
java/io/Closeable.class,
java/io/FilterOutputStream.class,
java/io/OutputStream.class,
java/io/Flushable.class,
java/lang/Comparable.class,
java/lang/CharSequence.class
]
[wrote RegularFileObject[HelloWorld.class]]
[total 277ms]
可以看到,javac 在编译的过程中使用到了 classpath, 其包含 jdk 内置的运行时 jar 包目录, class 目录, ext 目录, 以及用户代码的 classpath: (默认是 .)
编译的过程中,有两次加载 class 发生。分别是在 [checking HelloWorld] 之前和之后。
可以推断,第一次是验证 HelloWorld.java 时,对其依赖的 class 做递归式地加载,第二次是实现编译过程时,对过程中依赖的 class 加载。所以才看到有 io 相关的 class。
javac 对 rt.jar 下的 class 做了优化, 并没有直接引用,而是通过 ct.sym 去加载。
最后,将编译好的 class 写到文件: RegularFileObject[HelloWorld.class]
动态编译
动态编译的过程和静态编译类似, 带入代码我们来看下。
public static void compile(String className, String source, String outputDir) {
// JavaSourceFile: 实现了 JavaFileObject 的 source 实现.
JavaSourceFile sourceFile = new JavaSourceFile(className, source);
// 获取 compiler 实例
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
StandardJavaFileManager stdFileManager = compiler.getStandardFileManager(null, null, null);
// 拦截 fileManager 方法以指定 input 和 output
JavaFileManager fileManager = new ForwardingJavaFileManager<StandardJavaFileManager>(stdFileManager) {
@Override
public JavaFileObject getJavaFileForInput(
Location location, String className, JavaFileObject.Kind kind
) throws IOException {
return sourceFile;
}
};
// 编译诊断收集器
DiagnosticCollector<JavaFileObject> collector = new DiagnosticCollector<>();
// 构造编译任务
JavaCompiler.CompilationTask task = compiler.getTask(
new OutputStreamWriter(System.err),
fileManager,
collector,
Arrays.asList("-d", outputDir),
null,
Collections.singleton(sourceFile)
);
Boolean success = task.call();
if (!success) {
collector.getDiagnostics().forEach(System.err::println);
} else {
System.out.println("Compile success");
}
}
首先构造编译的原材料: 源代码 JavaFileObject, 然后向 jvm 获取 JavaCompiler 实例, 通过继承 JavaCompiler 下的 JavaFileManager 拦截了 getJavaFileForInput 方法。
现在要开始编译了:
在 sun 提供的 api 里,CompilationTask 就代表 shell 命令 javac HelloWorld.java。
getTask 接纳了 JavaFileManager, 编译诊断的收集器, 编译选项, 注解处理, 编译单元(source file)。
吐槽下 sun 提供的 api 其实并不优雅,
fileManager以及编译单元在getTask时感觉都可以省略。 另外fileManager默认和磁盘文件耦合太深,而动态编译通常都是在内存完成的。
最后,如果 task.call 返回了 true 则表示编译成功。那么问题来了,编译生成的 class 在哪儿呢?
有好几种实现方式,可以拦截 fileManager 的 getJavaFileForOutput 实现,也可以在通过在编译选项上增加 -d 选项指明 class 的输出目录。
个人认为后一种方式更灵活。
至此,动态编译完成。小结下:
- 动态编译的本质就是通过 java api 实现了在运行期执行 javac 命令这个过程。
- api 依赖的 jdk 内置的 jar 包 (位于 ext 目录的 tools.jar ),jre 无法完成。
所以说动态编译实际上依赖了运行时 jdk,不同 jdk 厂商的 api 可能会有差异。
在实现的时候可以参考 github 上比较完善的实现:
- Java-Runtime-Compiler: 开箱即用的企业级动态编译器, 支持缓存,
- compiler: 编译过程在内存完成,仅支持 java6, 已停止维护。
- Janino: drools 早期使用的动态编译器,功能强大,api 抽象层次较低,上手难度大。
在 Operator 实现
编译阶段
为了避免动态编译的 api 和 jdk 耦合,做的第一件事情就是将 java tools 这个 jar 包打进 fat jar 内部。
添加 dependency:
<dependency>
<groupId>com.perfma.wrapped</groupId>
<artifactId>com.sun.tools</artifactId>
<version>1.8.0_jdk8u275-b01_linux_x64</version>
</dependency>
在 compiler 解析 source code (A) 的时候,如果发现依赖了另外一些 class (B) 时,会尝试 load B。而 B 往往是用户代码 fat jar 的内容。
如果 fat jar 已经在当前 jvm 的 classpath 上了。那肯定可以找到,问题在于不是。
当 Flink Cluster 启动的时候,用户的 jar 还没有上传。Flink Cluster 启动了 JobManager 和 TaskManager 初始化对应的 Slots。
以 TaskManager 为例,其 classpath 可以在启动日志中看到:
2023-06-19 11:24:43,523 [main] INFO org.apache.flink.kubernetes.taskmanager.KubernetesTaskExecutorRunner [] - Classpath:
/flink/lib/flink-cep-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-connector-files-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-csv-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-json-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-metrics-log-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-metrics-prometheus-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-metrics-slf4j-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-ml-examples-2.1-1.0.0-SNAPSHOT.jar:
/flink/lib/flink-ml-uber-2.1-1.0.0-SNAPSHOT.jar:
/flink/lib/flink-queryable-state-runtime_*.jar:
/flink/lib/flink-scala_2.12-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-shaded-hadoop-2-uber-3.1.3-10.0-SNAPSHOT.jar:
/flink/lib/flink-shaded-zookeeper-3.5.9.jar:
/flink/lib/flink-statebackend-gemini_1.8-3.2.6-SNAPSHOT.jar:
/flink/lib/flink-state-processor-api-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-table-api-java-uber-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-table-planner-loader-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/flink-table-runtime-1.15-vvr-6.0.6-SNAPSHOT.jar:
/flink/lib/jersey-core-1.9.jar:
/flink/lib/log4j-1.2-api-2.17.1.jar:
/flink/lib/log4j-api-2.17.1.jar:
/flink/lib/log4j-core-2.17.1.jar:
/flink/lib/log4j-slf4j-impl-2.17.1.jar:
/flink/lib/flink-dist-1.15-vvr-6.0.6-SNAPSHOT.jar:
:
:
classpath 只包含 Flink 框架的 jar。用户提交的 fat jar 由 Flink 自定义的 ClassLoader (FlinkUserCodeClassLoader) 进行加载。
当用户通过 Flink 客户端将 Job 提交到 Cluster, JobManager 会将 fat jar 注册到 BlobService 并缓存到本地。
TaskManager 通过 rpc 向 JobManager 下载 fat jar 到本地,然后通过自定义的 ClassLoader 加载 jar 包,开始运行 StreamTask。
所以,在动态编译期,我们需要显式地指定 classpath,相当于告诉 javac 当前 fat jar 的路径。
List<String> options = new ArrayList<>();
options.add("-classpath");
StringBuilder sb = new StringBuilder();
// 通过 FlinkUserCodeClassLoader 获取 fat jar 路径
URLClassLoader urlClassLoader = (URLClassLoader) this.getClass().getClassLoader();
for (URL url : urlClassLoader.getURLs()) {
sb.append(url.getFile()).append(System.getProperty("path.separator"));
}
options.add(sb.toString());
log.info("FlinkUserCodeClassLoader classpath: {}", sb);
JavaCompiler.CompilationTask task = compiler.getTask(null, manager, collector, options, null, Collections.singletonList(source));
加载阶段
编译完成后,想要使用这个 class (A), 需要通过 ClassLoader 加载它。可以直接通过 FlinkUserCodeClassLoader,前提是将 编译完成的 class 置于其 classpath 路径中。
也可以自定义一个 ClassLoader,但是需要注意将它的 parent 设置为 FlinkUserCodeClassLoader。为什么?
因为如果不指定 parent ,那么通过 ClassLoader 源码可知,将会默认继承 SystemClassLoader 作为 parent:
// java.lang.ClassLoader.java:
protected ClassLoader() {
this(checkCreateClassLoader(), getSystemClassLoader());
}
而刚才我们看了, SystemClassLoader 的 classpath 只包含 Flink 框架的类库,所以不指定 parent 时, 是无法加载 user code 里的 class 的。
load 时会报: ClassNotFound。
最后用一张图来说明动态编译类的加载:
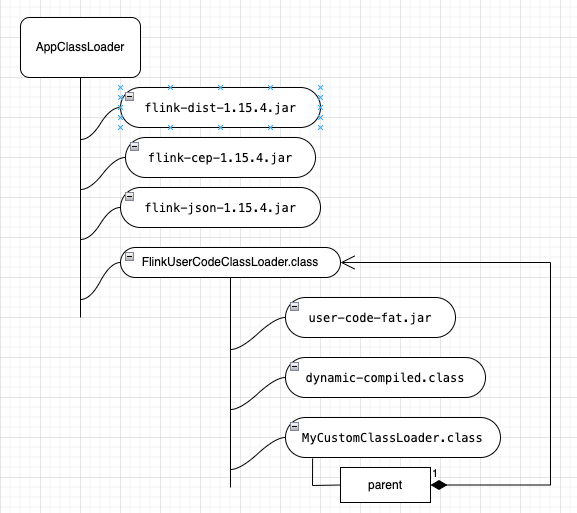
<<<EOF