在 macOS 上搭建 Iceberg
2024-02-23 [data-warehouse
hadoop
hive
spark
flink
iceberg
]
眼过千遍,不如手过一遍。本文将描述如何在 macOS 上搭建 Iceberg。 涉及到: Hadoop, Hive, Iceberg, Spark, Flink。
环境 & 版本
- OS: macOS Ventura (M2)
- Java: 1.8 (Amazon Corretto)
- Hadoop(hdfs): 3.3.6
- Hive: 2.3.9
- Iceberg: 1.4.3
- Spark: 3.5.0-hadoop3
- Flink: 1.18 (1.17)
Hadoop
从 Hadoop 官网 下载最新版,下载时注意对应 cpu 架构。
解压,配置环境变量:
export HADOOP_HOME=$HOME/opt/hadoop-3.3.6
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CONFIG_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
export YARN_CONFIG_DIR=$HADOOP_HOME/etc/hadoop
在 core-site.xml configurations 下添加如下配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
在 hdfs-site.xml 中添加如下配置:
<property>
<name>dfs.namenode.name.dir</name>
<value>{YOUR_NAME_NODE_DIR}</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>{YOUR_CHECKPOINT_DIR}</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>{YOUR_DATA_NODE_DIR}</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
这 3 个目录默认都是基于 hadoop.tmp.dir,而 hadoop.tmp.dir 的默认值是 /tmp/hadoop-${user-name}。
tmp 目录会由于操作系统策略被不定期 清空 ,导致 hdfs 出现数据一致性问题。
所以建议将 3 个目录设置到 tmp 之外。
初始化 namenode
hdfs namenode -format
启动
用 sbin/start-dfs.sh 启动 hdfs。用 jps -l | grep hadoop 查看进程是否启动:
46039 org.apache.hadoop.hdfs.server.namenode.NameNode
46185 org.apache.hadoop.hdfs.server.datanode.DataNode
46367 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
测试
hadoop fs -mkdir -p /tmp
hadoop fs -put README.txt /tmp
hadoop fs -cat /tmp/README.txt
Hive
下载,解压。
配置环境变量:
export HIVE_HOME=$HOME/opt/apache-hive-2.3.9-bin
export PATH=$HIVE_HOME/bin:$PATH
export HIVE_CONFIG_DIR=$HIVE_HOME/conf
为 hive 表配置 hdfs 目录:
hadoop fs -chmod g+w /tmp
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /user/hive/warehouse
配置 hive, 在 conf 目录下增加 hive-site.xml 文件,增加如下配置:
<property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>{YOUR_MYSQL_PASSWORD}<value>
</property>
这里主要是配置 metastore,我们使用 mysql 作为 metastore db,默认是 derby 数据库。
配置完成后需要执行命令进行初始化:
bin/schematool -dbType mysql -initSchema
初始化成功后,可以查看下 mysql 的表是否正常,然后:
- 启动 hive server:
bin/hiveserver2 - 启动 beeline client:
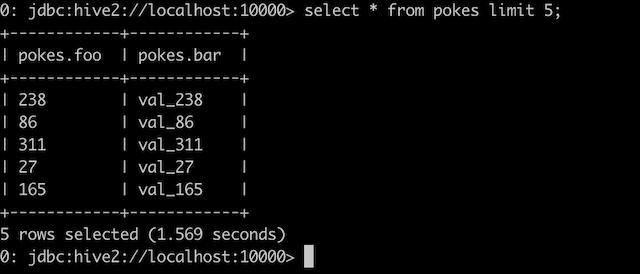
bin/beeline -u jdbc:hive2://localhost:10000
CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);
LOAD DATA LOCAL INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
SELECT * FROM invites LIMIT 5;
Issues
如果在 beeline client 连接 hiveserver 时出现: User: XXX is not allowed to impersonate anonymous (state=,code=0) 错误,
需要在 Hadoop core-site.xml 添加如下配置:
<property>
<name>hadoop.proxyuser.{YOUR_USER_NAME}.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.{YOUR_USER_NAME}.hosts</name>
<value>*</value>
</property>
其中 YOUR_USER_NAME 就是启动 hiveserver2 进程的用户,可以通过 whoami 获取。
这是因为 hive 默认会做一个 冒充 的行为: 冒充当前提交查询的这个用户来提交 hadoop mapred 任务。 而一个用户允许被哪些人冒充,需要在 hadoop 内进行配置。
详细的解释可以查看这里: Stack Overflow: Cannot connect to hive using beeline, user root cannot impersonate anonymous
Spark
下载,解压。
虽然 Spark 文档 说需要把
hive-site.xml 复制到 conf 目录下,但是我在实际测试过程中发现 Spark 会根据 HIVE_HOME 找到 hive 的 config,从而解析出 metastore。
所以只复制 core-site.xml 和 hdfs-site.xml 即可。
测试
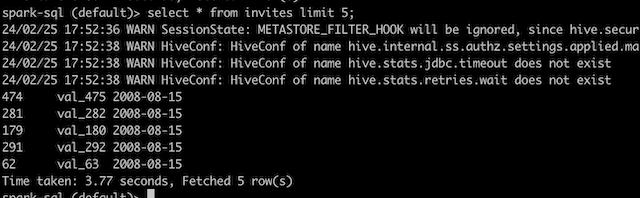
CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive;
LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src;
SELECT * FROM src LIMIT 5;
Flink
下载,解压。
修改配置 conf/flink-conf.yaml:
jobmanager.memory.process.size: 1600m
taskmanager.resource.id: static-tm-res-id
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 10
固化 resource id,调整 JM 和 TM 内存。
启动: bin/start-cluster.sh
访问 webUI 查看是否启动成功: http://localhost:9090/#/overview
测试
启动 bin/sql-client.sh
CREATE TABLE employees (
name VARCHAR,
salary INT
) WITH (
'connector' = 'filesystem',
'path' = '{SPARK_HOME}/examples/src/main/resources/employees.json',
'format' = 'json'
);
SELECT * FROM employees;
Issue
在启动 sql-client.sh 的时候,可能会遇到: java.lang.NoClassDefFoundError
Exception in thread "main" org.apache.flink.table.client.SqlClientException: Could not read from command line.
at org.apache.flink.table.client.cli.CliClient.getAndExecuteStatements(CliClient.java:221)
at org.apache.flink.table.client.cli.CliClient.executeInteractive(CliClient.java:179)
at org.apache.flink.table.client.cli.CliClient.executeInInteractiveMode(CliClient.java:121)
at org.apache.flink.table.client.cli.CliClient.executeInInteractiveMode(CliClient.java:114)
at org.apache.flink.table.client.SqlClient.openCli(SqlClient.java:169)
at org.apache.flink.table.client.SqlClient.start(SqlClient.java:118)
at org.apache.flink.table.client.SqlClient.startClient(SqlClient.java:228)
at org.apache.flink.table.client.SqlClient.main(SqlClient.java:179)
Caused by: java.lang.NoClassDefFoundError: Could not initialize class org.apache.flink.table.client.config.SqlClientOptions
at org.apache.flink.table.client.cli.parser.SqlClientSyntaxHighlighter.highlight(SqlClientSyntaxHighlighter.java:59)
at org.jline.reader.impl.LineReaderImpl.getHighlightedBuffer(LineReaderImpl.java:3633)
at org.jline.reader.impl.LineReaderImpl.getDisplayedBufferWithPrompts(LineReaderImpl.java:3615)
at org.jline.reader.impl.LineReaderImpl.redisplay(LineReaderImpl.java:3554)
at org.jline.reader.impl.LineReaderImpl.doCleanup(LineReaderImpl.java:2340)
at org.jline.reader.impl.LineReaderImpl.cleanup(LineReaderImpl.java:2332)
at org.jline.reader.impl.LineReaderImpl.readLine(LineReaderImpl.java:626)
at org.apache.flink.table.client.cli.CliClient.getAndExecuteStatements(CliClient.java:194)
... 7 more
这是因为 Flink 为了集成 Hadoop,会将 hadoop classpath 作为 classpath 一部分,查看 sql-client.sh 第 93 行:
exec "$JAVA_RUN" $FLINK_ENV_JAVA_OPTS $JVM_ARGS "${log_setting[@]}" -classpath "`manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS:$FLINK_SQL_CLIENT_JAR"`" org.apache.flink.table.client.SqlClient "$@" --jar "`manglePath $FLINK_SQL_CLIENT_JAR`"
由于 hadoop classpath 包含很多 jar,这些 jar 容易与 flink 依赖的 jar 产生版本冲突,所以解决方式是让 flink 的 jar 优先加载。
调整 classpath 的顺序:
exec "$JAVA_RUN" $FLINK_ENV_JAVA_OPTS $JVM_ARGS "${log_setting[@]}" -classpath "`manglePathList "$CC_CLASSPATH:$FLINK_SQL_CLIENT_JAR:$INTERNAL_HADOOP_CLASSPATHS"`" org.apache.flink.table.client.SqlClient "$@" --jar "`manglePath $FLINK_SQL_CLIENT_JAR`"
类似的错误可以参考这个: Issue(FLINK-33358): Flink SQL Client fails to start in Flink on YARN。
Flink 读取 Hive 表
不同于 Spark,Flink 查询 Hive 表时需要通过 Hive Thrift MetaServer。
- 启用 hive metastore server:
hive --service metastore - 在
{YOUR_FLINK_INSTALL_DIR}/conf下新建 hive-site.xml: 注意此 hive-site.xml 是提供给 Flink 访问 hive metastore 使用的,不是 hive 安装目录下的 hive-site.xml。 需要配置 metastore server 的地址和 hive dir 即可:<property> <name>hive.metastore.uris</name> <value>thrift://localhost:9083</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> - 将 flink-sql-connector-hive-2.3.9_2.12-1.18.1.jar 添加到
$FLINK_HOME/lib下。重启 flink cluster。 - 启动 sql-client.sh,增加 hive catalog:
CREATE CATALOG myhive WITH ( 'type' = 'hive', 'hive-conf-dir' = '{YOUR_FLINK_INSTALL_DIR}/conf' ); - Query:
Flink SQL> use catalog myhive; [INFO] Execute statement succeed. Flink SQL> show tables; +-------------+ | table name | +-------------+ | invites | | src | +-------------+ 4 rows in set Flink SQL> select * from src limit 5;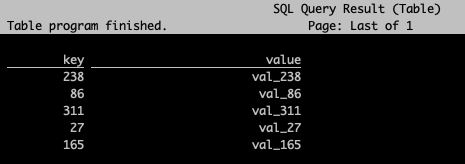
Iceberg
准备工作终于结束!接下来让我们回到 Iceberg 上。
Spark 访问 Iceberg
下载 iceberg-spark-runtime-3.5_2.12:1.4.3.jar 并添加到 $SPARK_HOME/lib 下。
我们使用 spark-sql 来访问 Iceberg。启动:
spark-sql \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.catalog.spark_catalog.type=hive \
--conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.local.type=hadoop \
--conf spark.sql.catalog.local.warehouse=/user/iceberg/warehouse
然后直接按照 文档 进行 DDL、DML、Query 操作就好:
CREATE TABLE local.db.table (id bigint, data string) USING iceberg;
INSERT INTO local.db.table VALUES (1, 'a'), (2, 'b'), (3, 'c');
SELECT count(1) as count, data
FROM local.db.table
GROUP BY data;
CREATE TABLE spark_catalog.default.invites_ice(foo INT, bar STRING) PARTITIONED BY (ds STRING) USING iceberg;
INSERT INTO spark_catalog.default.invites_ice SELECT * FROM spark_catalog.default.invites;
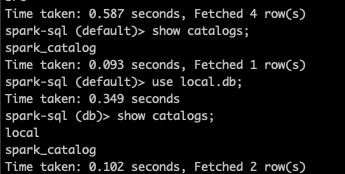
值得一提的是,Spark 的 catalog 是懒加载的。这意味如果你第一次进入到 spark-sql 的环境,直接用 show catalogs 是无法查看到 local 的。
必须先先引用其中的 db 或者 table。
Flink 访问 Iceberg
我们先将下载 iceberg-flink-runtime-1.17-1.4.3.jar 注意: 由于 Flink 1.18 版本比较新,目前 Iceberg 还没有适配。
我偷个懒,直接用 1.17 的包试验下。
启动 sql-client:
Flink SQL> CREATE CATALOG `local` WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='/user/iceberg/warehouse'
);
[INFO] Execute statement succeed.
Flink SQL> use catalog `local`;
[INFO] Execute statement succeed.
Flink SQL> select * from `table`;
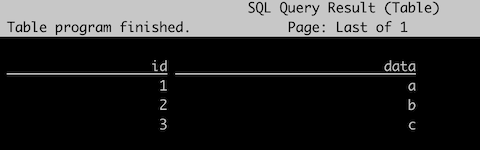
再来试下 使用 hive metastore 的 Iceberg 表:
Flink SQL> CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://localhost:9083',
'clients'='5',
'hive-conf-dir'='{YOUR_HIVE_CONFIG_DIR}',
'hadoop-conf-dir'='{YOUR_HADOOP_CONFIG_DIR}'
);
[INFO] Execute statement succeed.
Flink SQL> use `default`;
[INFO] Execute statement succeed.
Flink SQL> show tables;
+-------------+
| table name |
+-------------+
| invites_ice |
+-------------+
Flink SQL> select * from invites_ice;
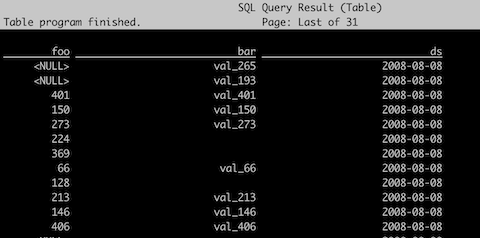
终于,我们可以使用 Spark 和 Flink 正常操作 Iceberg 表。
REF
- Hadoop: Setting up a Single Node Cluster.
- Hive: Getting Started
- Flink: Access Hive Table
- Iceberg: Spark Getting Started
<<<EOF