Flink 内存配置实践
2025-07-09 [flink
k8s
]
记一下在部署 Flink 任务时遇到的内存配置问题。
本地测试环境搭建
- OS: macOS Sequoia (arm64)
- Java: 1.8 (Amazon Corretto)
- Flink: 1.15.4
- Local K8S: Kind + Podman
- Arthas: 4.0.5
TaskManager
由于部署成功之后,我们的作业实际上运行在 tm 的 slot 里,所以我们优先看 tm 的内存配置。
我们先不管三七二十一,启动一个本地的 session 集群: bin/start-cluster.sh
然后通过 web ui 观察 tm 的内存模型:

大致介绍一下各个部分的内容:
JVM Heap:
- Framework Heap: 框架堆内存, 用于 Flink 框架的 JVM 堆内存。
- Task Heap: 任务堆内存, 用于 Flink 应用的算子及用户代码的 JVM 堆内存。
Off-Heap:
- Managed Memory: 托管内存, 由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存。
- Direct Memory:
- Framework Off-heap: 框架堆外内存, 用于 Flink 框架的堆外内存(直接内存或本地内存)。
- Task Off-heap: 任务堆外内存, 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存)。
- Network: 网络内存, 用于任务之间数据传输的直接内存(例如网络传输缓冲)。
- JVM Metaspace: Flink JVM 进程的 Metaspace。
- JVM Overhead: JVM 开销, 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。
其中,标记背景颜色的部份需要根据任务数据量调整。
Flink 在内存配置上支持 3 种模式:
- 只配置 进程 内存: 适用于 Yarn/K8S 等资源调度模式,进程内存直接和 K8S 的 resource.limit 对应起来。
- 只配置 Flink 内存: 适合本地调试,起一个 standard session cluster。
- 配置所有组件的内存: 精细化地管理每个组件的内存,相对复杂。
对于前两者,Flink 虽然屏蔽了底层细节,但内部也是通过一系列的计算得到各个组件的内存配置:
org/apache/flink/runtime/util/config/memory/ProcessMemoryUtils.java
public CommonProcessMemorySpec<FM> memoryProcessSpecFromConfig(Configuration config) {
if (options.getRequiredFineGrainedOptions().stream().allMatch(config::contains)) {
// all internal memory options are configured, use these to derive total Flink and
// process memory
return deriveProcessSpecWithExplicitInternalMemory(config);
} else if (config.contains(options.getTotalFlinkMemoryOption())) {
// internal memory options are not configured, total Flink memory is configured,
// derive from total flink memory
return deriveProcessSpecWithTotalFlinkMemory(config);
} else if (config.contains(options.getTotalProcessMemoryOption())) {
// total Flink memory is not configured, total process memory is configured,
// derive from total process memory
return deriveProcessSpecWithTotalProcessMemory(config);
}
return failBecauseRequiredOptionsNotConfigured();
}
在只配置了进程内存(process mem)的情况下,flink 会先计算出 metaspace 和 overhead 的内存,然后用 process - (metaspace + overhead) 得出 total flink mem。 再根据 total flink mem, 计算出各个子区域的大小。
让我们测试一下, conf/flink-conf.yaml:
# TaskManager settings
taskmanager.memory.process.size: 2g
计算流程如下:
- JVM Metaspace: 默认是 256m
- JVM Overhead: 默认是 process 内存的 0.1, 上下限: 1g/192m -> 2g * 0.1 = 204.8m
- Total flink mem: 2g - 256m - 204.8m = 1587.2m
- Off-heap:
- Managed: 1587.2m * 0.4 (fraction) = 634.88m
- Direct.Network: 1587.2m * 0.1 (fraction) 上下限: (1g/64m) = 158.72m
- Direct.Framework: 128m (default)
- Direct.Task: 0 (default)
- Heap memory:
- Framework: 128m (default)
- Task: Total flink memory - Off-heap - Heap.Framework: 1587.2m - 921.6m - 128m = 537.6m
启动 tm 后,观察日志:
INFO [] - Final TaskExecutor Memory configuration:
INFO [] - Total Process Memory: 2.000gb (2147483648 bytes)
INFO [] - Total Flink Memory: 1.550gb (1664299824 bytes)
INFO [] - Total JVM Heap Memory: 665.600mb (697932173 bytes)
INFO [] - Framework: 128.000mb (134217728 bytes)
INFO [] - Task: 537.600mb (563714445 bytes)
INFO [] - Total Off-heap Memory: 921.600mb (966367651 bytes)
INFO [] - Managed: 634.880mb (665719939 bytes)
INFO [] - Total JVM Direct Memory: 286.720mb (300647712 bytes)
INFO [] - Framework: 128.000mb (134217728 bytes)
INFO [] - Task: 0 bytes
INFO [] - Network: 158.720mb (166429984 bytes)
INFO [] - JVM Metaspace: 256.000mb (268435456 bytes)
INFO [] - JVM Overhead: 204.800mb (214748368 bytes)
查看 tm jvm flags:
> jcmd {TM_PID} VM.flags
...
-XX:InitialHeapSize=704643072
-XX:MaxHeapSize=704643072
-XX:MaxDirectMemorySize=300647712
-XX:MaxMetaspaceSize=268435456
...
通过对比可以看到彼此之间的关系:
| JVM Flag | Flink Component |
|---|---|
| -XX:MaxHeapSize | Total JVM Heap Memory(Framework + Task) |
| -XX:MaxDirectMemorySize | Total JVM Direct Memory(Framework + Task + Network) |
| -XX:MaxMetaspaceSize | JVM Metaspace |
小结: tm 的内存主要花在 Managed 和 Heap。
JobManager
jm 的内存模型如下, 和 tm 比较简单了很多

- JVM Heap: JobManager 的 JVM 堆内存。
- Off-Heap: JobManager 的堆外内存(直接内存或本地内存)。
- JVM Metaspace: Flink JVM 进程的 Metaspace。
- JVM Overhead: JVM 开销, 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。
其中 Heap 主要用于框架和 checkpoint 回调时用户代码执行。
对于 Off-heap,默认配置下,Flink JobManager 没有限制 Off-heap 的内存使用,通过: jobmanager.memory.enable-jvm-direct-memory-limit: true
可以对 jm jvm 进程增加 -XX:MaxDirectMemorySize 从而限制 Off-heap 内存使用。
jm 的内存配置和 tm 一样,遵循 3 中模式规则, conf/flink-conf.yaml:
jobmanager.memory.process.size: 1g
计算规则和 tm 类似:
- JVM Metaspace: 默认是 256m
- JVM Overhead: 默认是 process 内存的 0.1, 上下限: 1g/192m -> 1024g * 0.1 = 102.4m, 由于低于最小值, 用 192m
- JVM Off-heap: 默认是 128m
- JVM Heap: 1024m - 256m - 192m - 128m = 448m
观察 jm 的启动日志:
INFO [] - Final Master Memory configuration:
INFO [] - Total Process Memory: 1024.000mb (1073741824 bytes)
INFO [] - Total Flink Memory: 576.000mb (603979776 bytes)
INFO [] - JVM Heap: 448.000mb (469762048 bytes)
INFO [] - Off-heap: 128.000mb (134217728 bytes)
INFO [] - JVM Metaspace: 256.000mb (268435456 bytes)
INFO [] - JVM Overhead: 192.000mb (201326592 bytes)
观察 jm 的 vm flags:
> jcmd {SESSION_CLUSTER_PID} VM.flags
-XX:InitialHeapSize=469762048
-XX:MaxHeapSize=469762048
...
-XX:MaxMetaspaceSize=268435456
限制 direct-memory-limit 之后:
-Xmx469762048
-Xms469762048
-XX:MaxDirectMemorySize=134217728
-XX:MaxMetaspaceSize=268435456
并不影响 jvm 其它区域的内存分配。
常见问题
官方文档列举了几个常见问题
- OutOfMemoryError: Java heap space
- OutOfMemoryError: Direct buffer memory
- OutOfMemoryError: Metaspace
- IOException: Insufficient number of network buffers
具体的解决途径参考: 内存常见问题(官方)
Arthas
Arthas 是一款 Java 应用调试的工具,功能强大,底层依赖 JVM Agent 机制。想要运行 Arthas 一般都需要完整的 JDK。
依赖 JAVA_HOME/lib/tools.jar。
使用 K8S 部署时,我们的镜像一般会继承 Flink 官方的镜像,但是官方镜像的 JDK 并不是完整的 JDK。
并没有诸如 jcmd, jstat 等调试程序,也没有 tools.jar。
为了激活(attach) Arthas 的 agent,需要使用 jattach。 好在 jattach 在 ubuntu 上有 apt 包可以直接安装!
apt update && apt install jattach
jattach {JVM_PID} load instrument false /opt/arthas/arthas-agent.jar
然后观察目标 JVM 进程是否监听了 3658 端口
netstat -anlp
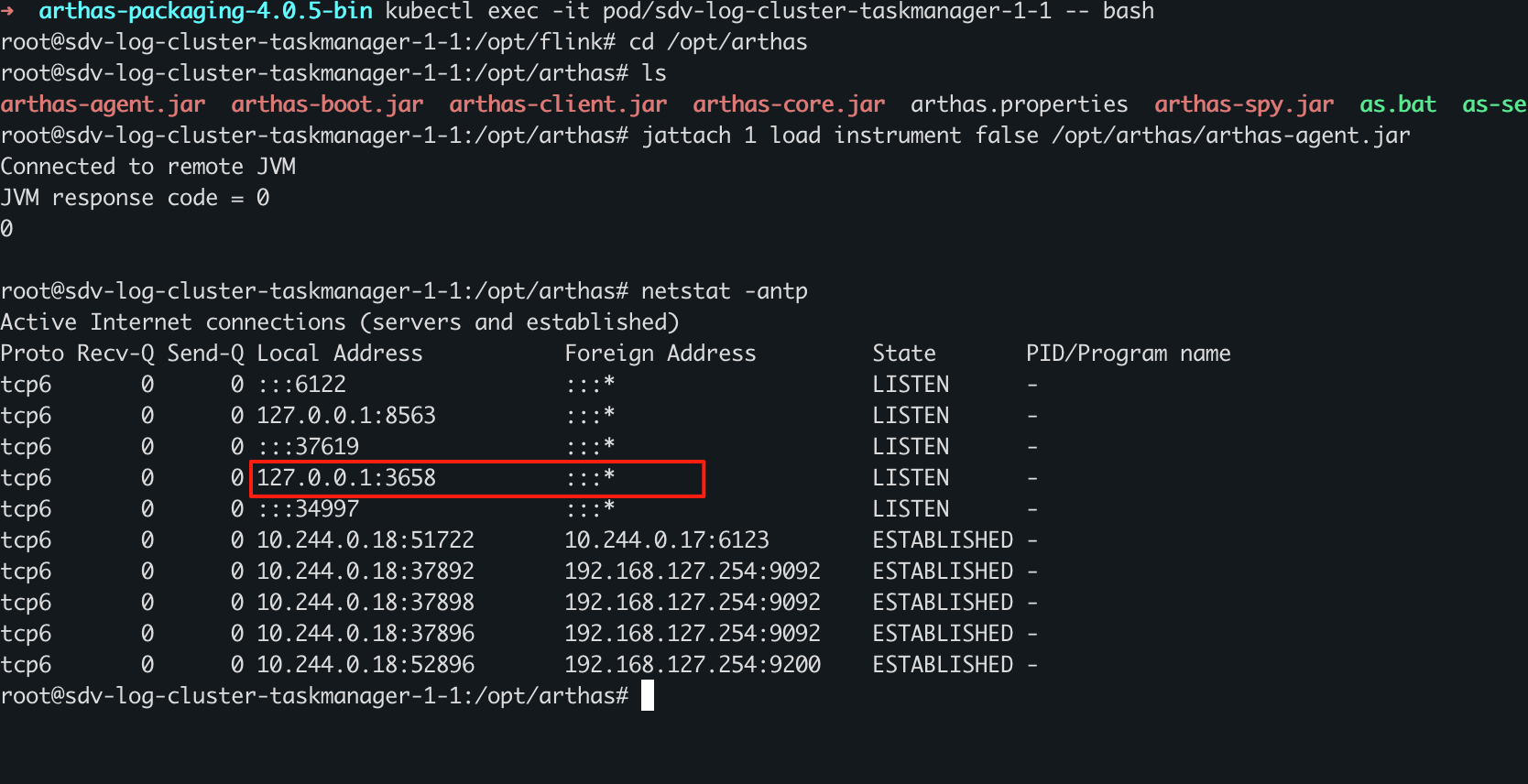
最后启动 arthas-client.jar 连接 3658 进行调试。
java -jar arthas-client.jar
REFs
<<<EOF