Flink 概念辨析 Operator, Task, Subtask, Slot
2025-07-29 [flink
concepts
]
记得刚开始学 Flink 的时候,看官方文档有时会被它的概念搞得头晕。今天我尝试在 Flink Dashboard 的帮助下快速厘清几个基本概念!
Operator, Task, Subtask, Slot。
首先可以先扫一遍 官方文档 中提到的这几个概念。
总结一下:
- Flink 在部署的时候,会将 算子(Operator) 组成 算子链(Operator Chain) 也就是 Task ,每个 Task 运行在单独的线程中,这样做的好处是减少数据交换、缓冲区开销等。
- Flink 提供的并行度机制,可以将 Task 转为多个并行的 SubTask 运行在各自的线程中。
- 每个 SubTask 都需要部署在 Slot 中运行。

- 来自同一个 Job 中的 SubTask 可以和除了自己的其它 Subtask 共享 Slot!
最后一点有点绕,就是说:一个 Job,虽然有多个 Subtask,但是它们可以部署在一个 Slot 中。所以就变成:一个 Slot 可以部署 Job 的一个并行度。

如图所示: 左侧 TM 的第一个 Slot 上部署了整个 Job。
如果说你看到这里还是有点懵,接下来我们自己创建一个 Demo 来理解。
创建 Demo
接下来我们准备一个 Demo 程序,并且提交到 Flink Standard Cluster 中:
代码如下:
KafkaSource<byte[]> kafkaSource = KafkaSource.<byte[]>builder()
.setBootstrapServers(kafkaConfig.bootstrapServers)
.setTopics(kafkaConfig.topicNames.heartbeat)
...
.build();
DataStream<Heartbeat> dataStream = streamEnv
.fromSource(
kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource"
)
.map(new HeartbeatMapper()).name("heartbeatMap").uid("heartbeatMap")
.filter(hb -> hb.getVin() != null).name("heartbeatFilter").uid("heartbeatFilter");
dataStream
.shuffle() // 手动触发
.addSink(new PrintSinkFunction<>()).uid("printSink").name("printSink");
代码非常简单: 从 Kafka 读取数据,然后进行 map, filter, shuffle 后通过 printSink 打印。
分析 Demo
在 Flink DataStream Api 中,Operator 就是算子,常见的有 Fliter/Map/Join 等。
上述代码的 HeartbeatMapper, Lambda Filter 都是 Operator。
Operator 是 User Api 层面(逻辑层) 的概念,最终运行的时候,会经过 Flink 框架一系列的优化,将 Operator 组成链:
可以看到,我们的作业被组成了 2 个链。组成算子链可以减少数据交换以带来性能提升。
算子链就是 Task,我们的作业包含两个 Task(蓝色方块)。每个 Task 都会交给 Slot 上运行。
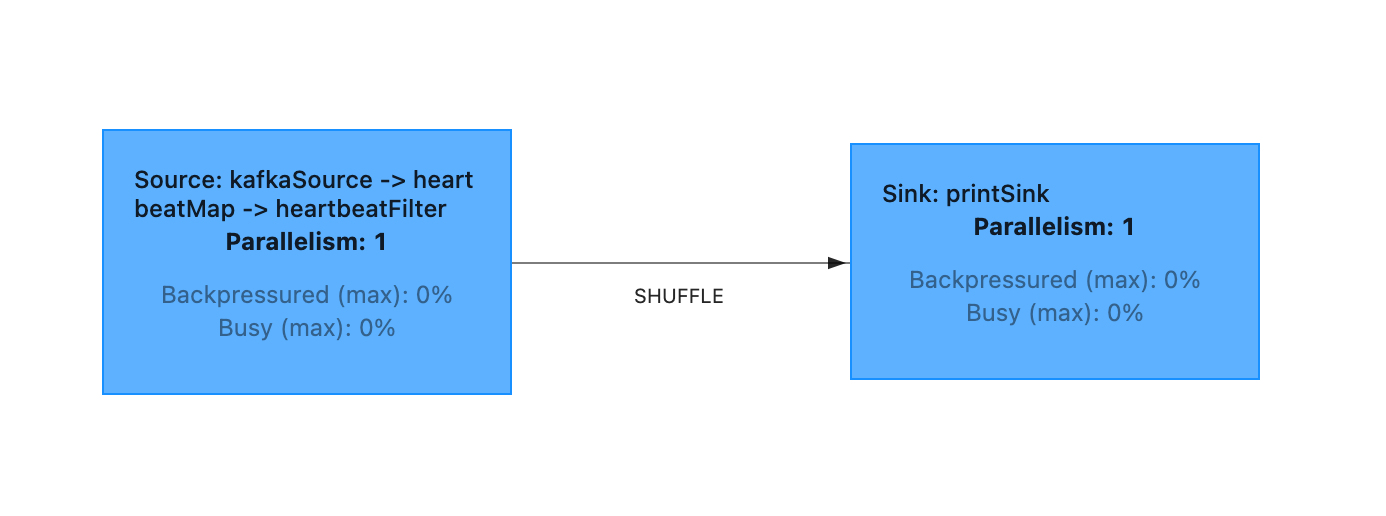
此时任务并行度为 1,Flink 集群 Slot 数量为 1 即可部署。
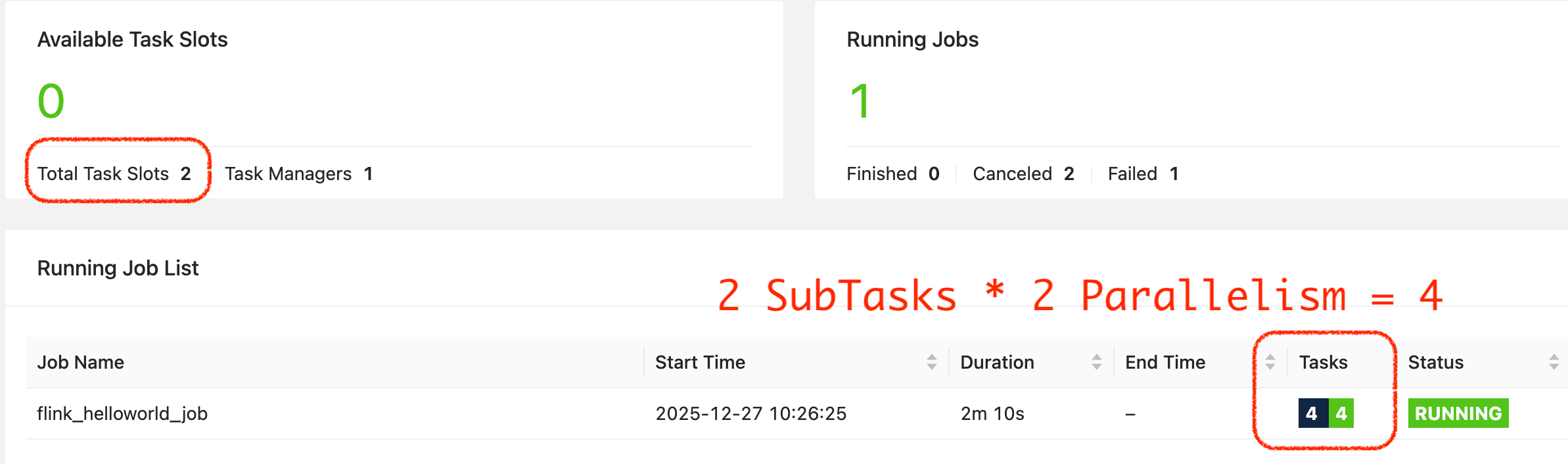
当并行度改为 2 时,1 个 Task 变为 2 个 SubTask,我们修改 Flink 集群的配置:
taskmanager.numberOfTaskSlots: 2
然后也可以正常部署:
最后我们进入到 TaskManager 页面,进行 Thread Dump:
"Source Data Fetcher for Source: kafkaSource -> heartbeatMap -> heartbeatFilter (2/2)#0" Id=151 RUNNABLE (in native)
at sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)
at sun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:198)
at sun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:117)
...
"Sink: printSink (2/2)#0" Id=142 TIMED_WAITING on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@6a776ec
at sun.misc.Unsafe.park(Native Method)
- waiting on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@6a776ec
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2163)
...
"Sink: printSink (1/2)#0" Id=141 TIMED_WAITING on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@648bd7b2
at sun.misc.Unsafe.park(Native Method)
- waiting on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@648bd7b2
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
...
"Source: kafkaSource -> heartbeatMap -> heartbeatFilter (2/2)#0" Id=140 TIMED_WAITING on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@34bf2376
at sun.misc.Unsafe.park(Native Method)
- waiting on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@34bf2376
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
...
可以清楚地看到我们的 4 个 SubTask。
至此,Flink 算子运行时模型已经基本清楚了,那么现在问题来了,知道 Slot 有什么用呢?
在自研大数据平台的时候,往往是基于 K8S 对 Flink 作业进行调度,那么每个任务配置了多少并行度,理论上就需要多少个 Slot,也就是多少个 TM。
单 Slot TM 的隔离性最好,就是一个 TM 专属于某一个作业。
<<<EOF